-
由
 虚拟的现实创建于11月 01, 2023
需要 2 分钟阅读时间
虚拟的现实创建于11月 01, 2023
需要 2 分钟阅读时间
5.5 分布式集群共识问题
为了提高系统的并发支持以及系统的容错能力,最常见的方案是将多个成员采用副本的形式组成一个集群,集群副本的方案要求多个成员之间保持数据对齐,才能提供正确的服务,当单个或少数成员发生故障时,并不影响整体的可用性。集群的核心问题在于多个成员如何实现对齐?答案就是状态机。
状态机
状态机(State Machine)来源于数学领域,它被定义为一组状态和一个转换函数。状态机从一个初始状态,每次输入都要传入转换函数,使得状态机进入一个新的状态,在下一个输入来之前,保持状态不变。状态机具有确定性,一个确定的输入只会转化到一个确定的状态。
这个特性可以保证多个状态机从相同的初始状态开始,按照相同的顺序将一系列输入传给转换函数之后,都会达到一致的状态。
状态机复制
我们可以将分布式中的节点看成一个个状态机,根据状态机的特性,只要保证它们的初始状态是一致的,并且接收的操作指令顺序也是一致,无论这个指令是新增、更新、删除亦或者其他任何可能的程序行为,并正确将这些一连串操作广播给各个分布式节点,期间允许系统内部状态存在不一致的情况,但最终所有节点的状态将是一致的,这种模型被称为状态机复制(State Machine Replication)。
5.5.1 什么是分布式集群共识?
基于状态机的分布式系统最关键的是决定输入的顺序,因为相同的输入顺序才能使所有的非错误成员达到相同的状态,这样才能保证每一个成员之间的数据一致性,并能随时构建无限个一模一样的状态机(分布式成员)。
为了使一组成员拥有相同的一组输入,我们需要在状态机上再设计一个保证协议,即共识算法。
共识算法
共识问题是指,在分布式系统中,要求一组成员根据它们的输入,就共同输出达成共识,在分布式环境中,每个成员都可能因为请求顺序而接受不同的值,并且每个成员都可能发生故障,因此,想让所有的成员按照相同的顺序执行一系列操作并不容易。实现这一过程,能让分布式集群即使是在部分节点故障、网络延时、网络分割的情况下,仍能最终表现出整体一致的过程,就被称为各个节点的协商共识。
共识算法更多用于提高系统的容错性,共识算法的目的允许让分布式系统内部暂时存在不一致的状态,但要保证大多数节点的状态达成一致。同时,在外部看来,集群系统要始终保证整体一致性的状态。Paxos、ZAB、Raft 都属于共识算法。
但是,还是要注意,分布式事务 和 共识协议解决的是两类问题:
- 2PC 等协议解决的是分布式事务一致性,目标侧重于 ACID。
- Paxos/raft 解决的是副本间数据的一致性和高可用,存储的数据完全一致,目标侧重于集群系统容错能力。
5.5.2 共识算法 Raft
Raft 是工程上使用较为广泛的强一致性、去中心化、高可用的分布式共识算法。Raft 从问世就开始备受关注,被认为是所有共识算法中的最优解,无论是协商效率还是工程实现,效果都非常出色。
1. Raft 的基本概念
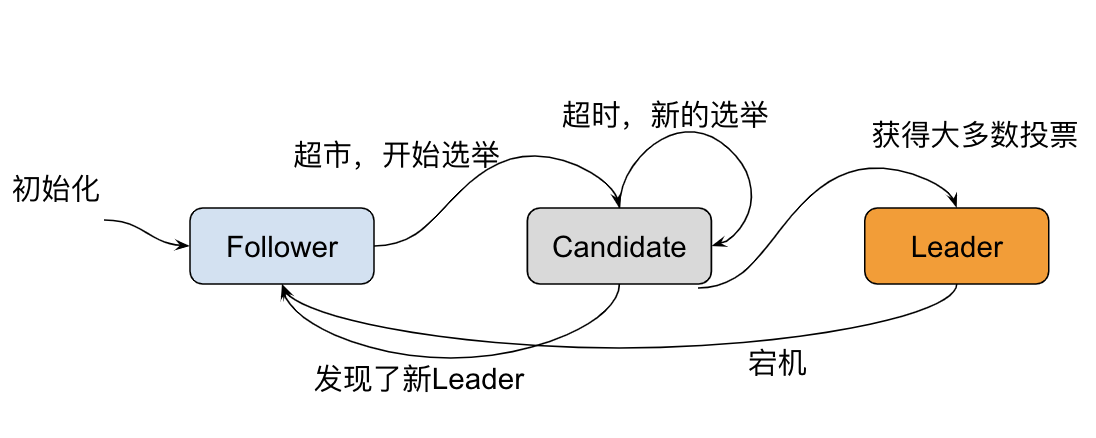
Raft 将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选者(Candidate)
- Leader:接受客户端请求,并向 Follower 同步请求日志,当日志同步到大多数节点上后高速 Follower 提交日志。
- Follower:接受并持久化 Leader 同步的日志,在 Leader 告知日志可以提交后,提交日志。当 Leader 出现故障时,主动推荐自己为候选人。
- Candidate:Leader 选举过程中的临时角色。向其他节点发送请求投票信息,如果获得大多数选票,则晋升为 Leader
Raft 算法将分布式一致性分解为多个子问题,包括 Leader 选举(Leader election)、日志复制(Log replication)、安全性(Safety)、日志压缩(Log compaction)等。
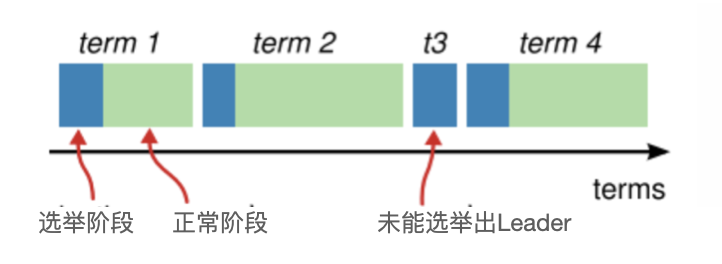
Raft 算法将时间划分为不定长度的任期 Terms,Terms 为连续的数字。每个 Term 以选举开始,如果选举成功,则由当前 leader 负责出块,如果选举失败,并没有选举出新的单一 Leader,则会开启新的 Term,重新开始选举。
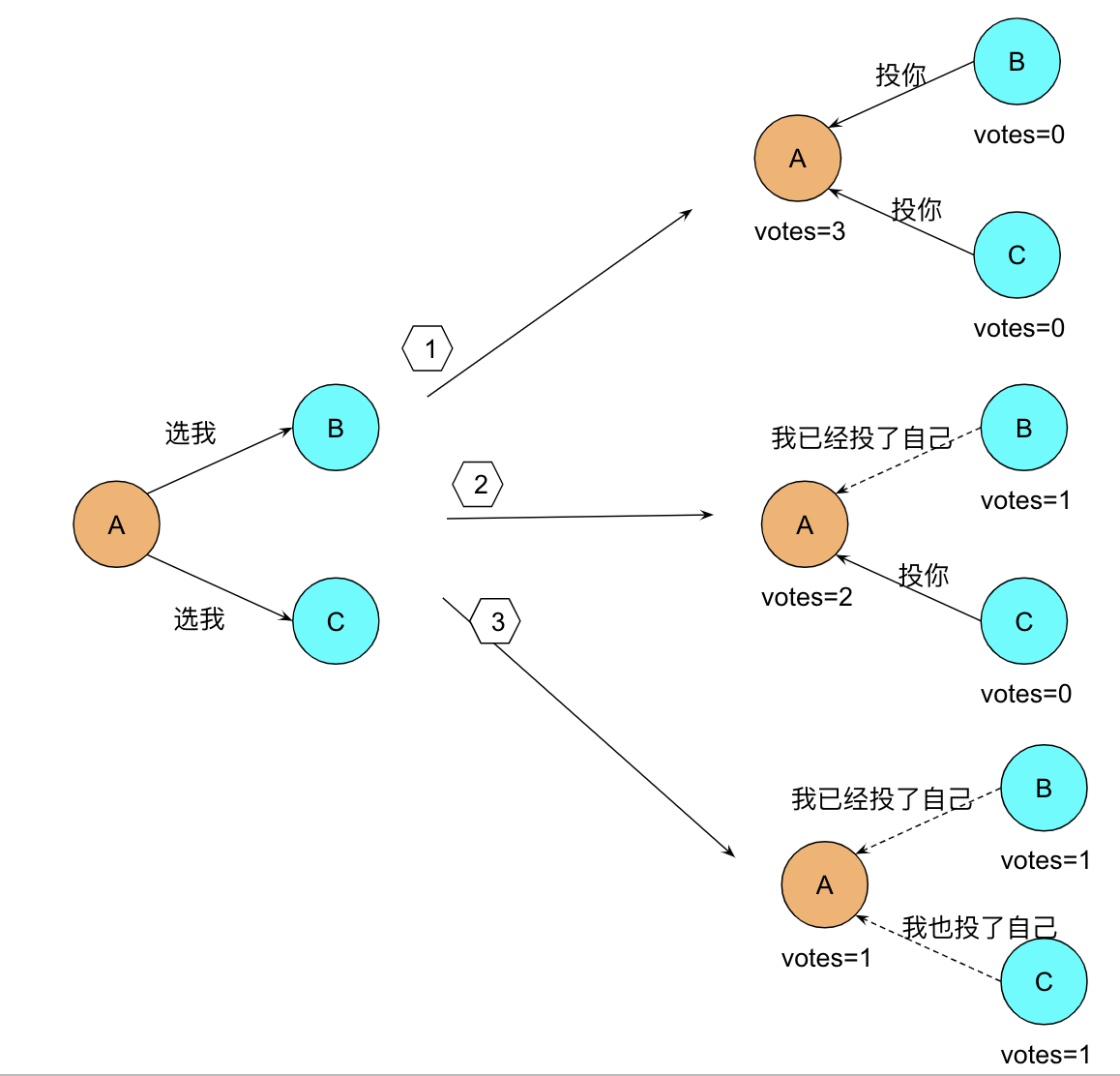
Leader 选举
Raft 使用心跳机制来触发领导者选举,当服务器启动时,初始化都是 Follower 身份,由于没有 Leader,Followers 无法与 Leader 保持心跳,因此 Followers 会认为 Leader 已经下线,进而转为 Candidate 状态,然后 Candidate 向集群其他节点请求投票,同意自己成为 Leader,如果 Candidate 收到超过半数节点的投票(N/2 +1),它将获胜成为 Leader。
Leader 向所有 Follower 周期性发送 heartbeat,如果 Follower 在选举超时时间内没有收到 Leader 的 heartbeat,就会等待一段随机的时间后发起一次 Leader 选举。
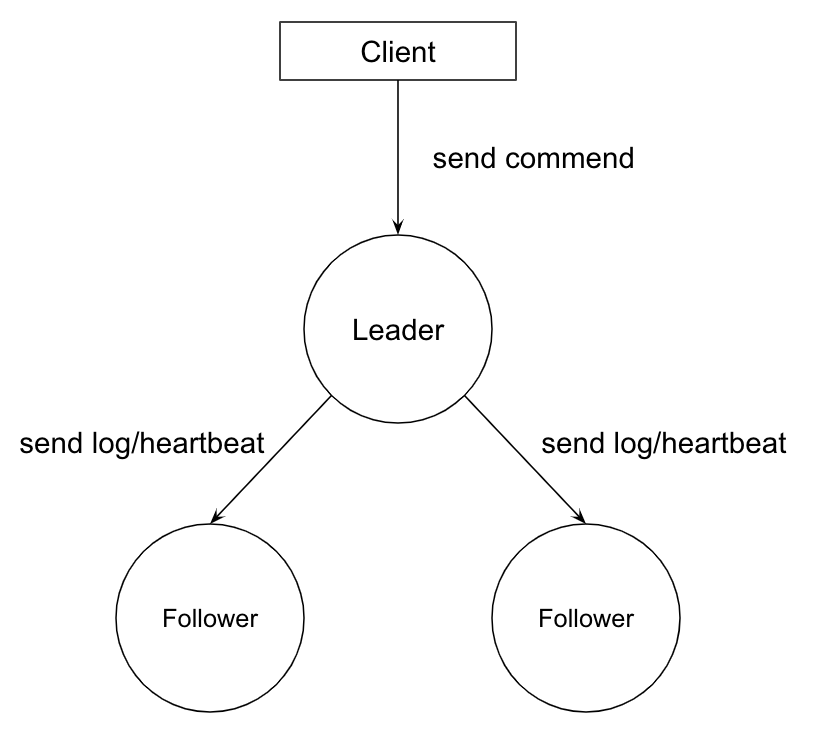
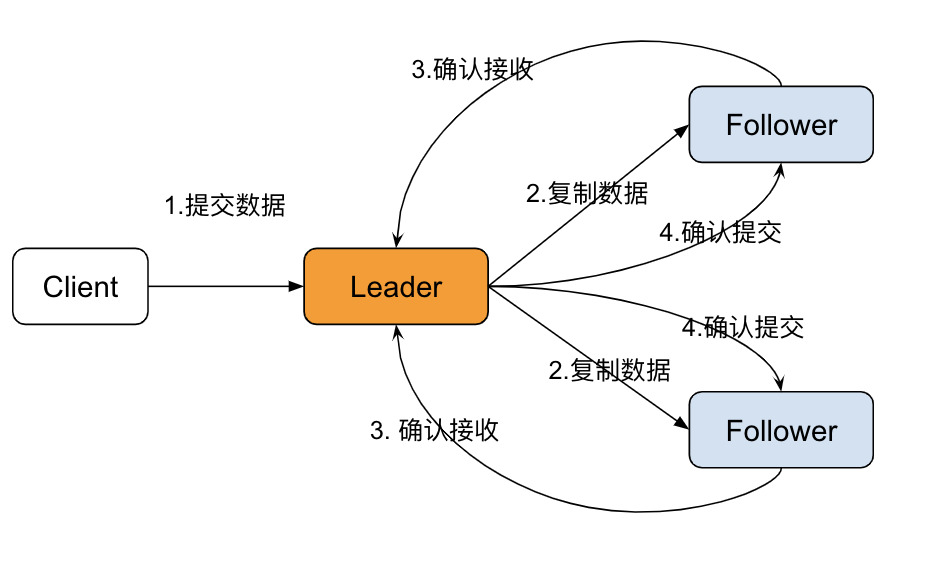
日志同步
Raft 算法实现日志同步的具体过程如下:
- Leader 收到来自客户端的请求,将之封装成 log entry 并追加到自己的日志中;
- Leader 并行地向系统中所有节点发送日志复制消息;
- 接收到消息的节点确认消息没有问题,则将 log entry 追加到自己的日志中,并向 Leader 返回 ACK 表示接收成功;
- Leader 若在随机超时时间内收到大多数节点的 ACK,则将该 log entry 应用到状态机并向客户端返回成功。
2. Raft 工程实现
Raft 拥有不同的开发语言多种实现,如下表展示了部分 Raft 工程实现
| 项目 | 开发语言 | Leader 选举+日志复制 | 持久化 | 成员变更 | 日志复制 |
|---|---|---|---|---|---|
| etcd/raft | Go | 支持 | 支持 | 支持 | 支持 |
| RethinkDB | C++ | 支持 | 支持 | 支持 | 支持 |
| TiKV | Rust | 支持 | 支持 | 支持 | 支持 |
| SOFAJRaft | java | 支持 | 支持 | 支持 | 支持 |
| braft | C++ | 支持 | 支持 | 支持 | 支持 |
如果是 Java 开发者,可以尝试使用 SOFAJRaft。 SOFAJRaft 是一个蚂蚁金服开源的高性能生产级类库,SOFAJRaft 除了提供单元测试之外,还可以使用 Jepsen 分布式一致性和线性化的安全性,以及模拟各种分布式场景。
感兴趣的读者可以在 https://raft.github.io 获取更多信息
添加评论