-
创建者:
 虚拟的现实,上次更新时间:12月 01, 2025
需要 2 分钟阅读时间
虚拟的现实,上次更新时间:12月 01, 2025
需要 2 分钟阅读时间
1. Kubernetes
容器技术解决了运行环境的隔离和迁移、交付等问题。但容器通常都在集群上运行,共享整个集群资源,从而也带来一个新的问题,那就是集群中容器如何自动部署、如何管理、联网,以及如何保证容器的可用性和扩展性?
解决上面的问题,就需要一个从集群角度进行整体规划,实现容器部署、迁移、管理、扩展和联网等等自动化的系统,即容器编排系统。这也是 Kubernetes 出现的背景。
Kubernetes 起源于 Google 的 Borg 系统,Borg 是在 2003 年 开发的一个大规模集群管理系统,用于支持 Google 内部成千上万的应用服务,Kubernetes 的设计思想完全沿用了 Borg 的设计思路,也就是说 Kubernetes 开源之前,Google 已经在容器以及容器治理方便已经有十几年的经历和探索了。
2. Kubernetes 与云原生
典型的云原生技术包括:容器、服务网格、微服务、不可变基础设施、声明式 API 等。
为了构建和推行云原生技术, Google 牵头成立了 CNCF (Cloud Native Computing Foundation, 云原生基金会),Kubernetes 就是 CNCF 的首个项目。Kubernetes 作为一个基础平台,整合并支持这些核心云原生技术,例如采用容器作为底层引擎,采用不可变基础设施进行构建和运行应用,采用声明式 API 对外提供服务,支持 Service mesh 对服务进行扩展等等,因为 Kubernetes 是云原生架构的核心和基石。
3. 8.1 声明式 API
声明式的东西是对最终结果的陈述,表明意图而不是实现它的过程,
Kubernetes 能力是通过各类 API 对象来提供,这些 API 对象有用来描述应用,有的则是为应用提供各种各样的服务,但无一例无,为了使用这些 API 对象提供的能力,都需要编写一个对应的 YAML 文件交给 Kubernetes。围绕使用 YAML 文件对 Pod 进行编排操作,可以分为命令式配置文件操作和声明式 API。
我们创建一个 yaml,然后进行 kubectl create -f yaml 的操作后,我们应用的 Pod 就会运行起来了,这个时候如果想要更新镜像我们可以直接修改原 yaml 文件,然后执行命令 kubectl replace -f yaml 来完成这次 deploy 的更新。
对于上面这种先 kubectl create,再 replace 的操作,我们称为命令式配置文件操作。它的处理方式只不过是把配置写在了 yaml 文件中而已。
那么,到底什么才是“声明式 API”呢?答案是,kubectl apply 命令。
kubectl replace 的执行过程,是使用新的 YAML 文件中的 API 对象,替换原有的 API 对象;而 kubectl apply,则是执行了一个对原有 API 对象的 PATCH 操作。更进一步地,这意味着 kube-apiserver 在响应命令式请求(比如 kubectl replace)的时候,一次只能处理一个写请求,否则会有产生冲突的可能。而对于声明式请求(比如 kubectl apply),一次能处理多个写操作,并且具备 Merge 能力。
3.1. 小结
总结 Kubernetes 中的声明式,指的就是我们只需要提交一个定义好的 API 对象来`声明”,我所期望的状态是什么样子。然后我们允许多个 API 写端对 API 期望状态进行修改,而无需关注其他人修改了什么,最后,k8s 在无需外界干预的情况就可以完成整个实际状态到期望状态的 Reconcile,可以毫不夸张的说,声明式 API,是 k8s 项目编排能力的核心所在
4. 8.2 多租户与资源隔离
企业组织在使用 Kubernetes 时,为简化运维以及降低资源成本,通常组织内各个部门、团队需要共享使用 Kubernetes 集群(多租户)。Kubernetes 集群并非天然地支持多租户,但它提供了一些列可被用于实现多租户的基础功能,基于这些功能,Kubernetes 社区也出现了一批较为成熟的多租户实现方案。
4.1. 多租户的隔离性
Kubernetes 中多租户的隔离性集中在两个方面:
- 控制面的隔离性,主要是隔离不同租户间能够访问哪些 API。
- 数据面的隔离性,比如说业务在实际运行起来之后,不能去占用别人的计算资源、存储资源等。
4.1.1. 控制面的隔离
Kubernetes 提供了三个机制来实现控制平面的隔离:namespace、RBAC 和 quota。
- Namespace 来做资源组织和划分,使用多 Namespace 可以将包含很多组件的系统分成不同的组。此外,namespace 也限定 RBAC 以及 quota 的作用范围。
- RBAC 被用来限定用户或者负载对 API 的访问权限。通过设定合适的 RBAC 规则,可以实现对 API 资源的隔离访问。
- ResourceQuota 可以被用来限制 namespace 下各类资源的使用上限,以防止某个 namespace 占据过多的集群资源而影响其他 namespace 下的应用。不过使用 ResourceQuota 有一个限制条件,即要求 namespace 下的每个容器都指定 resource request 和 limit。
4.1.2. 数据平面隔离
数据平面的隔离主要分为三个方面:容器运行时、存储和网络。
- 由于容器和宿主机共享内核,应用程序或者主机系统上的漏洞可能被攻击者所利用,从而突破容器边界而攻击到主机或者其他容器。解决方法通常是将容器放到一个隔离的环境中运行,例如虚拟机或者是用户态 kernel。前者以 Kata Containers 为代表,后者的代表则是 gVisor。
- 存储的隔离应保证 volume 不会跨租户访问。由于 StorageClass 是集群范围的资源,为防止 PV 被跨租户访问,应指定其 reclaimPolicy 为 Delete。此外,也应禁止使用例如 hostPath 这样的 volume,以避免节点的本地存储被滥用。
-
网络隔离:Namespace 的组织上划分对运行的对象来说,它不能做到真正的隔离。举例来说,如果两个 Namespace 下的 Pod 知道对方的 IP,而 Kubernetes 依赖的底层网络没有提供 Namespace 之间的网络隔离的话,那这两个 Pod 就可以互相访问。Kubernetes 提供了 NetworkPolicy,支持按 Namespace 级别的网络隔离,需要注意的是,使用 NetworkPolicy 需要特定的网络解决方案,如果不启用,即使配置了 NetworkPolicy 也无济于事,生产环境中可以 Calico 配合 NetworkPolicy 实现业务需要的安全组策略。
4.2. 多租户解决方案
Kubernetes 社区有许多开源项目专门解决多租户问题。从大方向上,它们分为两类。一类是以 namespace 为边界划分租户,另一类则为租户提供虚拟控制平面
4.2.1. 按 namespace 划分租户
Kubernetes 的控制平面隔离中的 RBAC 和 ResourceQuota 均以 namespace 为边界,因此以 namespace 来划分租户是比较自然的想法。不过,在现实中,限定一个租户只能使用一个命名空间存在较大局限性。例如无法进一步以团队,或者以应用为粒度进行细分,造成一定的管理难度。因此 Kubernetes 官方提供了支持层级化 namespace 的 controller。此外,第三方开源项目例如 Capsule 和 kiosk 提供了更为丰富的多租户支持。

4.2.2. 虚拟控制平面
另一种多租户的实现方案是为每个租户提供一个独立的虚拟控制平面,以彻底隔离租户的资源。
虚拟控制平面的实现方式通常是为每个租户运行一套独立的 apiserver,同时利用 controller 将租户 apiserver 中的资源同步到原 Kubernetes 集群中。每个租户只能访问自己对应的 apiserver,而原 Kubernetes 集群的 apiserver 则通常不对外访问。
这类方案的代价是额外的 apiserver 的开销,但能够获得更为彻底的控制平面隔离。结合数据平面的隔离技术,虚拟控制平面可以实现更为彻底和安全的多租户方案。此类方案以 vcluster 项目为代表。

4.3. 小结
通常来说,按 namespace 划分租户的隔离性和自由度会略有欠缺,但优势在于轻量。对于多团队共享使用的场景,按 namespace 划分租户较为合适。而对于商业用户共享使用的场景,选择虚拟控制平面通常能够提供更好的隔离保障。
5. 8.3 Kubernetes 系统架构
Kubernetes 是典型的主从架构。有两部分组成:管理者被称为 Control Plane(控制平面)、被管理者称为 Node(节点)。
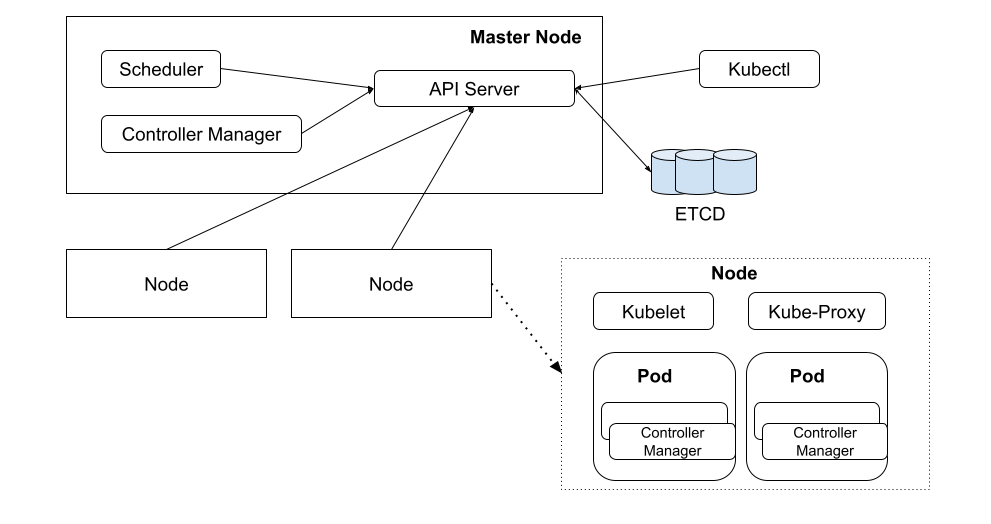
图 Kubernetes 架构
5.1. 1. Control Plane
Control Plane 是集群管理者,在逻辑上只有一个。按照习惯称呼,我们也可把该计算机称之为 Master 节点。Control Plane 对节点进行统一管理,调度资源并操作 Pod,它的目标就是使得用户创建的各种 Kubernetes 对象按照其配置所描述的状态运行。它包含如下组件:
- API Server: 操作 Kubernetes 各个资源的应用接口。并提供认证、授权、访问控制、API 注册和发现等机制。
- Scheduler(调度器):负责调度 Pod 到合适的 Node 上。例如,通过 API Server 创建 Pod 后,Scheduler 将按照调度策略寻找一个合适的 Node。
- Controller Manager(集群控制器):负责执行对集群的管理操作。例如,按照预期增加或者删除 Pod,按照既定顺序系统一系列 Pod。
5.2. 2. Node
Node 通常也被称为工作节点,可以有多个,用于运行 Pod 并根据 Control Plane 的命令管理各个 Pod,它包含如下组件:
- Kubelet 是 Kubernetes 在 Node 节点上运行的代理,负责所在 Node 上 Pod 创建、销毁等整个生命周期的管理。
- Kube-proxy 在 Kubernetes 中,将一组特定的 Pod 抽象为 Service,Kube-proxy 通过维护节点上的网络规则,为 Service 提供集群内服务发现和负载均衡功能。
- Container runtime (容器运行时):负责 Pod 和 内部容器的运行。在第七章已经介绍过各类容器运行时,Kubernetes 支持多种容器运行时,如 containerd、Docker 等。
0 评论