-
由
 管理员创建于11月 01, 2023
需要 1 分钟阅读时间
管理员创建于11月 01, 2023
需要 1 分钟阅读时间
分布式理论与实践
分布式系统的引入带来一个明显的问题是如何实现数据的一致性,以及分布式集群整体可用性。
- 微服务架构中,由于遵循数据存储隔离(Data Storage Segregation, DSS) 原则,当某个业务贯穿多个微服务时,这些微服务的数据分属不同的数据库,彼此的微事务也是独立的。这种情况需要解决的问题是如何实现业务层面的
大事务。 - 其次为了提高系统的可用性,以及容错性,数据服务通常采用数据副本(分布式集群)的形式,但在实际的环境中,必然面临网络不可靠、节点故障等问题,这种情况要解决的问题是如何保障集群服务的一致性和高可用。
对于如何构建一个兼顾可用性和一致性的分布式系统,也成了业内一直探索的难题,出现了诸如 CAP、BASE 这样的经典分布式理论。 对于解决分布式事务也出现了 传统两阶段提交(2PC)、补偿机制的 TCC、Saga 等模式以及一系列的共识算法 Paxos、ZAB、Raft 等。
这些分布式理论、算法不仅应用于区块链、后端开发等领域,在常见的中间件开发也能见到它们的身影,因此了解它们,知道它们的优缺点,才能设计出更加适合自己业务场景的系统架构。
5.1 BASE 理论及应用
BASE 是 Basically Available(基本可用)、Soft State(软状态)和 Eventually Consistent(最终一致性)三个短语的缩写。
BASE 理论是分布式系统中一致性和可用性权衡的结果,其核心思想是在某些场景中,无需做到强一致性,以保证系统的可用性,同时业务系统可采用适当的方式使数据达到最终一致性。
BASE 理论的三个方面:
-
基本可用: 是指分布式系统出现不可预知的故障时,允许损失系统部分特性来换取系统可用性。损失系统部分特性通常包括两个方面:响应时间的损失和功能降级。
- 响应时间的损失:当部分节点宕机时,在请求增加响应时间的基础上返回客户端正常的结果,而不是停止服务。
- 功能降级:当处于流量高峰时,一部分用户请求会返回降级的数据,而不会真正请求后端的核心数据,以保证后端系统大部分用户访问的可用性。
-
软状态:是指允许系统中的数据存在中间状态,并认为该中间状态的存在不影响整体系统的可用性。即允许系统在不同节点的数据副本之间进行数据同步时存在延时。对比 ACID 中的原子性,事务结束之后不会存在残留的中间状态,而 BASE 理论的软状态则允许事务出现中间状态。譬如,节点之间的投票协商和多副本之间的数据同步都需要进行网络交互,交互过程中的状态及即是软状态的一种体现。
-
最终一致性:强调系统中所有的数据副本,在经过一段时间同步后,最终能够达到一个一致的状态。BASE 理论允许事务出现中间状态,但经过一定的时间后,要求事务结束,所有的操作要么全部成功、要么全部失败。
BASE 理论应用
BASE 理论应用与多个微服务之间的调用。微服务的架构中,一个用户的请求往往需要多个服务配合才能完成,对于一个强一致性系统的可用性,都是所依赖服务可用性的乘积,例如,在一个事物中,涉及三个服务的操作,假设每个服务的可用性为 99.9%,则整个事务的可用性为 99.9% * 99.9% * 99.9% ≈ 99.7%。
现代的应用架构中,通常由几十甚至几百个微服务组成,对于如何提高整体系统的可用性,可用 BASE 理论进行指导,在允许存在软状态的基础上,我们只需要保证整个事务的基本可用性和最终一致性即可,并不需要保证实时一致性,保障性的设计,通常采用异步补偿机制。
例如,在一个电商系统中,下单需要三个服务支持。
- 访问支付服务,通知银行扣款
- 访问库存服务,扣除购买商品的库存
- 访问积分服务,为用户增加积分。
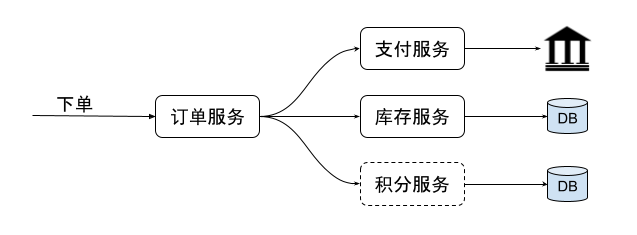
如果采用异步补偿机制,则需要明确哪些操作属于非关键操作,如果非关键操作失败,允许业务流程继续执行,然后再异步补偿非关键操作,以此降低非关键操作失败对整个事务的影响。
在上述电商案例中,我们可以将积分服务定义为非关键操作,非关键操作失败后,可以通过定时任务或者消息队列在下单完成后再给用户增加积分。而支付以及库存操作为关键操作,当其中任意一个发生故障时,我们都需要回滚本次事务。
采用异步补偿机制需要注意以下几点:
- 每个补偿操作都应该设置重试机制,且需要实现幂等。
- 整个事务应由工作流驱动,记录每个分支操作的处理结果。
- 对于所有分支事务,都需要提供回滚事务的接口。
5.2 CAP 定理
首先,CAP 是学术描述性的理论,它并不解决工程问题。在设计分布式系统架构中,通常基于 CAP 理论,并结合业务特点进行设计指导,通过适当取舍最大限度提升整体架构可用性。
CAP 是在 ACID 的一致性(Consistency,简写 C),BASE 的可用性(Availability,简写 A)两者基础上扩展出了一个新的维度:即分区容错性(Partition tolerance,简写 P),以此组成 CAP 定理。
CAP 定理的核心思想是:一个分布式系统其一致性(C)、可用性(A)和分区容错性(P),最多只能同时满足其中两项。
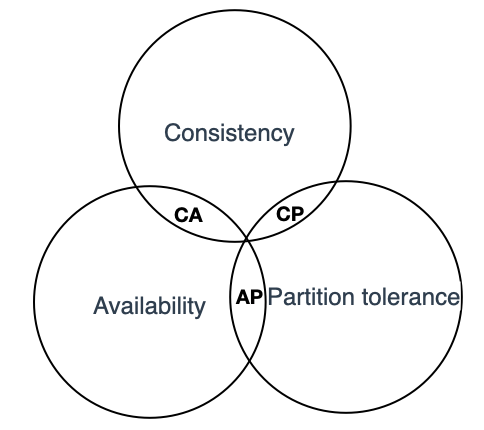
1. CAP 定理描述
-
一致性:被形容为原子性和串行化,每个读写操作都像是一个原子操作,并且像全局排好序一样,后面的读操作一定能读到前面的写操作。这意味着在分布式系统中执行一个操作就像在单节点执行一样。
-
可用性:是指系统提供的服务必须还一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里需要注意“有限时间内”和“返回结果”。如果时间处理的延时以及结果匹配性存在异常,那么我们认为系统是不可用的。
-
分区容错性:分布式的存储系统会有很多的节点,这些节点都是通过网络进行通信。而网络是不可靠的,当节点和节点之间的通信出现了问题,此时,就称当前的分布式存储系统出现了分区。分区容错性约束了一个分布式系统需要具有如下特征:分布式系统在遇到任何网络分区故障时,仍然需要能够保证对外提供满足一致性和可用性的服务,除非整个网络环境发生故障。
2. CAP 定理的应用
CAP 的指导作用是在架构设计中,不要浪费精力去设计一个满足一致性、可用性、分区容错性三者完美的系统,而是根据自己业务的特点就行取舍。值得注意的是,CAP 中的一致性和可用性表现为强一致性和完全(100%)可用性。
对于一个分布式系统而言,因为网络必然会出现异常情况,一旦发生分区错误,整个分布式系统就完全无法使用,分区容错性也就成了必然要面对和解决的问题,因此系统架构师往往需要把精力花在如何根据业务特点在 C(一致性)和 A(可用性)之间寻求平衡。
而根据一致性和可用性的选择不同,开源的分布式系统往往又被分为 CP 系统和 AP 系统。例如 CP 系统 Zookeeper,任何时刻对 ZooKeeper 的访问请求保证能得到一致的数据结果,而另外的 AP 系统 Eureka,则保证 A,当分区发生故障时,保证可用性但无法保证数据一致性。
5.3 事务处理特性 ACID
事务处理几乎是每一个信息系统中都会涉及到的问题,它存在的意义就是保证系统中不同数据间不会产生矛盾,数据修改后的结果是我们期望的,也就是保证数据状态的一致性(Consistency)。
想要达成数据状态的一致性,需要三个方面的努力:
- 原子性(Atomic):在一组操作中,要么全部操作执行成功,要么全部执行失败,不存在中间数据,也不存在部分操作成功部分操作失败的情况。在执行事务的过程中,如果某一个操作失败,那么整个事务都将回滚(Rollback),恢复至事务开始的状态。
- 隔离性(Isolation):多个事务在执行期间,事务与事务之间互不影响。
- 持久性(Durability):事务执行成功后,所有的操作都是永久的,哪怕服务器发生故障。
这也就是事务中 ACID 的概念,A I D 是手段,C(Consistency) 是三者协作的目标。
0 评论