-
由
 管理员创建于11月 01, 2023
需要 3 分钟阅读时间
管理员创建于11月 01, 2023
需要 3 分钟阅读时间
3.3.1 网卡多队列优化
内核处理一个数据包会有各类的中断处理、协议栈封装转换等繁琐流程,当收到的数据包速率大于单个 CPU 处理速度的时,因为分配给 RX/TX 队列的空间是有限的,Ring Buffer 可能被占满并导致新数据包被自动丢弃。
如果在多核 CPU 的服务器上,网卡内部会有多个 Ring Buffer,网卡负责将传进来的数据分配给不同的 Ring Buffer,同时触发的中断也可以分配到多个 CPU 上处理,这样存在多个 Ring Buffer 的情况下 Ring Buffer 缓存的数据也同时被多个 CPU 处理,就能提高数据的并行处理能力。
当然,要实现“网卡负责将传进来的数据分配给不同的 Ring Buffer”,网卡必须支持 Receive Side Scaling(RSS) 或者叫做 multiqueue 的功能。RSS 除了会影响到 NIC 将 IRQ 发到哪个 CPU 之外,不会影响别的逻辑。
1. 判断是否需进行优化
诸如集群核心交换节点、负载均衡服务器等场景的 PPS(Packet Per Second,包每秒)指标存在一定的优化空间且这些核心节点影响了集群业务,那我们可以查看系统状态以决定是否进行内核优化,首先我们确定是否存在丢包状况。
查询网卡收包情况 (RX 为收到的数据、TX 为发送的数据)。
$ ifconfig eth0 | grep -E 'RX|TX' RX packets 490423734 bytes 193802774970 (180.4 GiB) RX errors 12732344 dropped 9008921 overruns 3723423 frame 0 TX packets 515280693 bytes 140609362555 (130.9 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
以上查询结果中,RX dropped 表示数据包已经进入了 Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃,RX overruns 错误为 Ring Buffer 传输的 IO 大于 kernel 能够处理的 IO 导致,为 CPU 无法及时处理中断而造成 Ring Buffer 溢出。
2. RSS 下的多队列调整
RSS(receive side steering,多队列处理)利用网卡多队列特性,将每个核分别跟网卡的一个首发队列绑定,以达到网卡硬中断和软中断均衡的负载在各个 CPU 中,RSS 要求网卡必须要支持多队列特性。(注意:对于大部分驱动,修改以下配置会使网卡先 down 再 up,因此会造成丢包!)
2.1 多队列调整
查询 RX/TX 队列配置和使用情况。
$ ethtool -l eth0 Channel parameters for eth0: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 8 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 4
可以看到硬件最多支持 6 个,当前使用了 4 个。将 RX/TX 队列数量都设为 8。
$ ethtool -L eth0 combined 8
2.2 队列大小调整
增大 RX/TX 队列大小可以在 PPS(packets per second,包每秒)很大时缓解丢包问题。
- 首先查看队列大小。
$ ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 1024 RX Mini: 0 RX Jumbo: 0 TX: 1024 Current hardware settings: RX: 512 RX Mini: 0 RX Jumbo: 0 TX: 512
以上输出显示网卡最多支持 1024 个 RX/TX 数据包大小,但是现在只用到了 512 个。
- 通过 ethtool -G 命令修改队列大小。
$ ethtool -G eth0 rx 1024
但是注意开启多核并发特性,会挤压业务代码的执行时间,如果业务属于 CPU 密集型,会导致业务性能下降。是否开启多核处理,需要根据业务场景考虑。例如负载均衡服务器、网关、集群核心转发节点等网络 I/O 密集型场景可以尝试优化 RSS、RPS 等配置。
3.3.2 内核协议栈优化
一个传输少量数据的 TCP 连接生命周期中,握手、挥手阶段会占用了 70% 的资源消耗。高并发环境中,针对性地优化较为保守内核参数是提升服务处理能力的必要手段。
在本文,将介绍内核协议栈中 TCP 握手流程中队列、挥手 TIME_WAITE、Keepalive 保活原理及参数设置。
1. TCP 握手流程
如图 3-16 所示,握手流程中有两个队列比较关键,当队列满时多余的连接将会被丢弃。

图 3-16 TCP 握手概览
- SYN Queue(半连接队列)是内核保持未被 ACK 的 SYN 包最大队列长度,通过内核参数 net.ipv4.tcp_max_syn_backlog 设置。
- Accept Queue(全连接队列) 是 socket 上等待应用程序 accept 的最大队列长度,取值为 min(backlog,net.core.somaxconn)。
backlog 创建 TCP 连接时设置,用法如下。
int listen(int sockfd, int backlog)
2. TCP 连接保活
TCP 建立连接后有个发送一个空 ACK 的探测行为来保持连接(keepalive),保活机制受以下参数影响:
- net.ipv4.tcp_keepalive_time 最大闲置时间
- net.ipv4.tcp_keepalive_intvl 发送探测包的时间间隔
- net.ipv4.tcp_keepalive_probes 最大失败次数,超过此值后将通知应用层连接失效
大规模的集群内部,如果 keepalive_time 设置较短且发送较为频繁,会产生大量的空 ACK 报文,存在塞满 RingBuffer 造成 TCP 丢包甚至连接断开风险,可以适当调整 keepalive 范围减小空报文 burst 风险。
3. TCP 连接断开
由于 TCP 双全工的特性,安全关闭一个连接需要四次挥手,如图 3-17 所示。但复杂的网络环境中存在很多异常情况,异常断开连接会导致产生“孤儿连”,这种连接既不能发送数据,也无法接收数据,累计过多,会消耗大量系统资源,资源不足时产生 Address already in use: connect 类似的错误。

图 3-17 TCP 挥手概览
“孤儿连”的问题和 TIME_WAIT 紧密相关。TIME_WAIT 是 TCP 挥手的最后一个状态,当收到被动方发来的 FIN 报文后,主动方回复 ACK,表示确认对方的发送通道已经关闭,继而进入 TIME_WAIT 状态,等待 2MSL 时间后关闭连接。如果发起连接一方的 TIME_WAIT 状态过多,会占满了所有端口资源,则会导致无法创建新连接。
可以尝试调整以下参数减小 TIME_WAIT 影响:
- net.ipv4.tcp_max_tw_buckets,此数值定义系统在同一时间最多能有多少 TIME_WAIT 状态,当超过这个值时,系统会直接删掉这个 socket 而不会留下 TIME_WAIT 的状态
- net.ipv4.ip_local_port_range,TCP 建立连接时 client 会随机从该参数中定义的端口范围中选择一个作为源端口。可以调整该参数增大可选择的端口范围。
TIME_WAIT 问题在反向代理节点中出现概率较高,例如 client 传来的每一个 request,Nginx 都会向 upstream server 创建一个新连接,如果请求过多, Nginx 节点会快速积累大量 TIME_WAIT 状态的 socket,直到没有可用的本地端口,Nginx 服务就会出现不可用。
4. 相关配置参考
笔者整理了部分内核参数配置,以供读者参考。但注意使用场景不同和机器配置不同,相关的配置起到的作用也不尽相同,生产环境中的参数配置,得在知晓原理基础上,根据实际情况进行调整。
net.ipv4.tcp_tw_recycle = 0 net.ipv4.tcp_tw_reuse = 1 net.ipv4.ip_local_port_range = 1024 65535 net.ipv4.tcp_rmem = 16384 262144 8388608 net.ipv4.tcp_wmem = 32768 524288 16777216 net.core.somaxconn = 8192 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.core.wmem_default = 2097152 net.ipv4.tcp_max_tw_buckets = 5000 net.ipv4.tcp_max_syn_backlog = 10240 net.core.netdev_max_backlog = 10240 net.netfilter.nf_conntrack_max = 1000000 net.ipv4.netfilter.ip_conntrack_tcp_timeout_established = 7200 net.core.default_qdisc = fq_codel net.ipv4.tcp_congestion_control = bbr net.ipv4.tcp_slow_start_after_idle = 0
3.3.3 内核旁路技术
笔者 3.2.2 节介绍了半 kernel bypass 的 XDP 技术,这一节,我们再介绍完全 kernel bypass 的技术。
高并发下网络协议栈的冗长流程是最主要的性能负担,也就是说内核才是高并发的瓶颈所在。既然内核是瓶颈所在,那很明显解决方案就是想办法绕过内核。经很多前辈先驱的研究,目前业内已经出现了很多优秀内核旁路(kernel bypass)思想的高性能网络数据处理框架,如 6WIND、Wind River、Netmap、DPDK 等。其中,Intel 的 DPDK 在众多方案脱颖而出,一骑绝尘。
DPDK(Data Plane Development Kit,数据平面开发套件) 为 Intel 处理器架构下用户空间高效的数据包处理提供了库函数和驱动的支持,它不同于 Linux 系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。也就是 DPDK 绕过了 Linux 内核协议栈对数据包的处理过程,在用户空间实现了一套数据平面来进行数据包的收发与处理。
在内核看来,DPDK 就是一个普通的用户态进程,它的编译、连接和加载方式和普通程序没有什么两样,如图 3-18 所示,DPDK 与 传统内核网络的对比。
- 左边是原来的方式:数据从网卡 -> 驱动 -> 协议栈 -> Socket 接口 -> 业务。
- 右边是 DPDK 方式:基于 UIO(Userspace I/O)旁路数据。数据从网卡 -> DPDK 轮询模式-> DPDK 基础库 -> 业务。
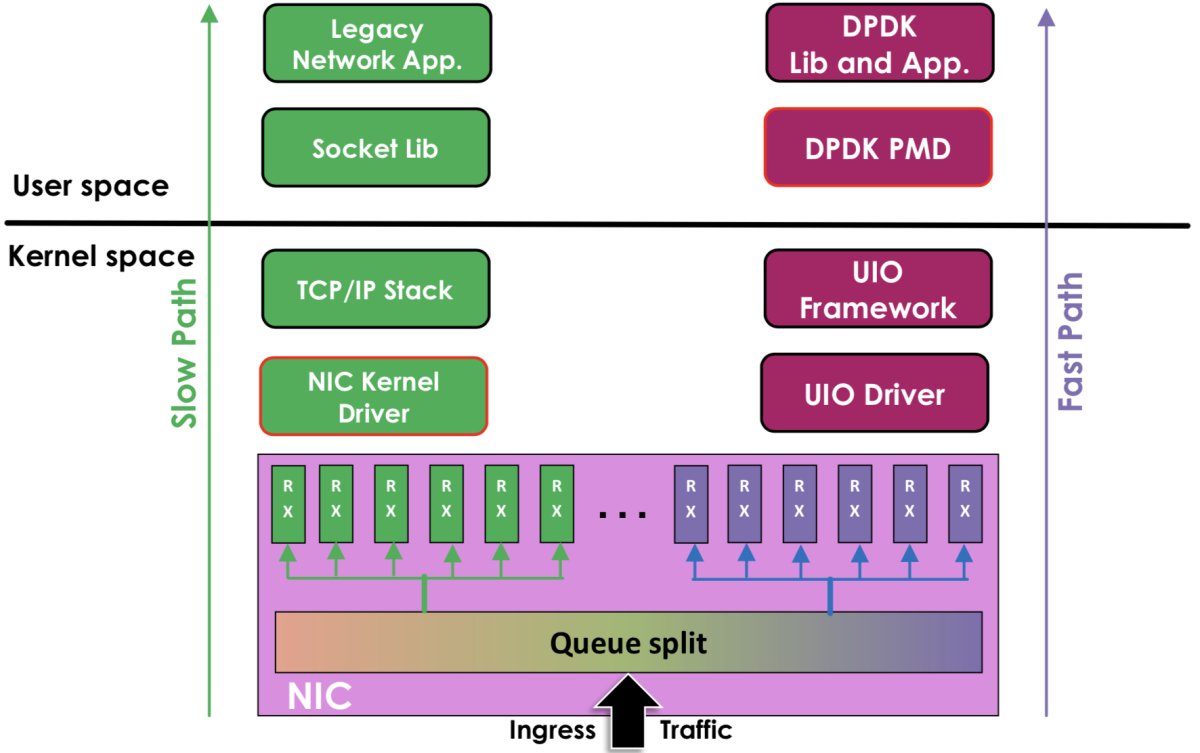
图 3-18 DPDK 与传统内核网络对比
很多企业如 Facebook 的 Katran、美团的 MGW、爱奇艺的 dpvs 等使用 DPDK、eBPF 技术进行 kernel bypass,直接全部在用户态进行数据包的处理,正是基于此,才得以实现单机千万并发的性能指标。
如图 3-19 所示,dpvs 与 lvs 在 PPS 转发上的指标对比,dvps 性能提升约 300%。

图 3-19 dpvs 性能指标对比
对于海量用户规模的互联网应用来说,动辄需要部署数千、甚至数万台服务器,如果能将单机性能提升 10 倍甚至百倍,无论是从硬件投入还是运营成本上来看都能带来非常可观的成本削减,这样的技术变革带来的潜在效益非常诱人。
添加评论