-
创建者:
 管理员,上次更新时间:11月 01, 2023
需要 4 分钟阅读时间
管理员,上次更新时间:11月 01, 2023
需要 4 分钟阅读时间
3.2 Linux 内核网络框架
网络协议栈的处理是一套相对固定和封闭的流程,整套处理过程中,除了网络设备层能看到一点点程序以设备的形式介入处理的空间外,其他过程似乎就没有什么可提供程序插手的空间了。然而事实并非如此,从 Linux Kernel 2.4 版本起,内核就开放了一套通用的,可提供代码干预数据在协议栈流转的过滤框架 – Netfilter。
如图 3-3 所示,该架构图来自 Netfilter 项目^1,图片名称为 《Packet flow in Netfilter and General Networking》,该设计图较全面介绍了内核网络设计原理,包含了 XDP、Netfilter 和 traffic control 部分。带颜色的部分为 Netfilter 模块,有着更细节的内核协议栈各 hook 点位置和 iptables 规则优先级的经典配图。

图 3-3 网络数据包流程和 Netfilter 框架
Netfilter 实际上就是一个过滤器框架,Netfilter 在网络包收发以及路由的“管道”中,一共切了 5 个口(hook),分别是 PREROUTING、FORWARD、POSTROUTING、INPUT 以及 OUTPUT,其它内核模块(例如 iptables、IPVS 等)可以向这些 hook 点注册处理函数。每当有数据包留到网络层,就会自动触发内核模块注册在这里的回调函数,这样程序代码就能够通过回调函数来干预 Linux 的网络通信,进而实现对数据包过滤、修改、SNAT/DNAT 等各类功能。
如图 3-4 所示,Kubernetes 集群服务的本质其实就是负载均衡或反向代理,而实现反向代理,归根结底就是做 DNAT,即把发送给集群服务的 IP 地址和端口的数据包,修改成具体容器组的 IP 地址和端口。

图 3-4 Kubernetes 服务本的质
如图 3-5 Kubernetes 网络模型说明示例,当一个 Pod 跨 Node 进行通信时,数据包从 Pod 网络 Veth 接口发送到 cni0 虚拟网桥,进入主机协议栈之后,首先会经过 PREROUTING hook,调用相关的链做 DNAT,经过 DNAT 处理后,数据包目的地址变成另外一个 Pod 地址,再继续转发至 eth0,发给正确的集群节点。

图 3-5 kubernetes 网络模型
对 Linux 内核网络基本了解之后,我们再来看看 Netfilter 和它的上层应用 iptables。
^1: 参见 https://en.wikipedia.org/wiki/Netfilter
3.2.1 iptables 与 Netfilter
以 Netfilter 为基础的应用很多,其中使用最广泛的无疑要数 Xtables 系列工具,譬如iptables、ebtables、arptables 等。 用过 Linux 系统的开发人员或多或少都使用过 iptables,它常被称为 Linux 系统”自带的防火墙“,然而 iptables 能做的事情已经远超防火墙的范畴,严谨地讲,iptables 的定位应是能够代替 netfilter 多数常规功能的 IP 包过滤工具。
Netfilter 的钩子回调固然强大,但仍要通过程序编码才能使用,并不适合系统管理员日常运维,而设计 iptables 的目的便是以配置的方式实现原本用 Netfilter 编码才能做到的事情。iptables 在用户空间管理数据包处理规则,内核中 Netfilter 根据 iptables 的配置对数据包进行处理,它们的关系如图 3-6 所示。
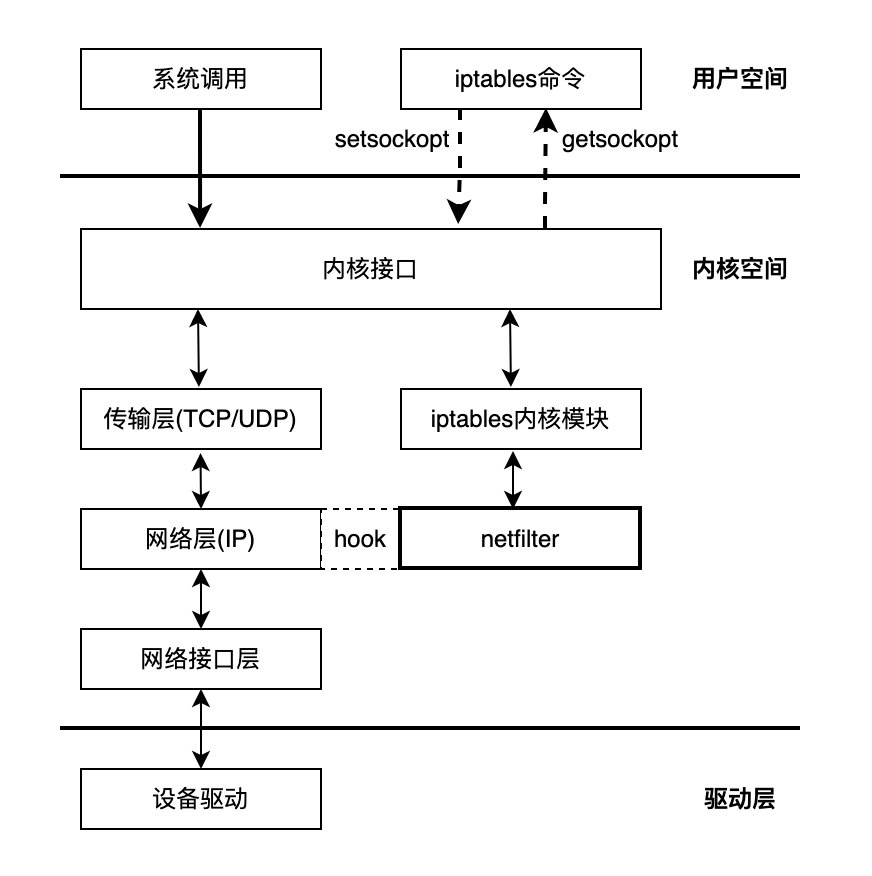
图3-6 iptables 与 Netfilter 的关系
1. iptables 表和链
iptables 包括了“tables(表)”、“chain(链)”和“rules(规则)”三个层面。iptables 使用表来组织规则,如果规则是处理网络地址转换的,那会放到 nat 表,如果是判断是否允许包继续向前,那可能会放到 filter 表。每个表内部规则被进一步组织成链,链由内置的 hook 触发后数据包依次匹配里面的规则。
这几个内置链的功能如下:
- PRETOUTING: 接收到的包进入协议栈后立即触发此链,在进行任何路由判断(将包发往哪里)之前。
- INPUT: 接收到的包经过路由判断,如果目的是本机,将触发此链。
- FORWARD 接收到的包经过路由判断,如果目的是其他机器,将触发此链。
- OUTPUT: 本机产生的准备发送的包,在进入协议栈后立即触发此链。
- POSTROUTING: 本机产生的准备发送的包或者转发的包,在经过路由判断之后,将触发此链。
如图3-7所示,一个目的是本机的数据包依次经过 PRETOUTING 链上面的 mangle、nat 表,然后再依次经过 INPUT 链的 mangle、filter、nat表,最后到达本机某个具体应用。

图3-7 iptables 中 chain 和 table 关系
2. iptables 自定义链
iptables 规则允许数据包跳转到其他链继续处理,同时 iptables 也支持创建自定义链,不过自定义链没有注册到 Netfilter hook,所以自定义链只能通过从另一个规则跳转到它。

图3-8 iptables 自定义链
自定义链可以看作是对调用它的链的扩展,自定义链结束的时候,可以返回 netfilter hook,也可以再继续跳转到其他自定义链,这种设计使 iptables 具有强大的分支功能,管理员可以组织更大更复杂的网络规则。
kubernetes 中 kube-proxy 组件的 iptables 模式就是利用自定义链模块化地实现了 Service 机制,其架构如图3-9 所示。KUBE-SERVICE 作为整个反向代理的入口链,KUBE-SVC-XXX 为具体某一服务的入口链,KUBE-SEP-XXX 链代表某一个具体的 Pod 地址和端口,即 Endpoint。KUBE-SERVICE 链会根据具体的服务 IP 跳转至具体的 KUBE-SVC-XXX 链,然后 KUBE-SVC-XXX 链再根据一定的负载均衡算法跳转至 Endpoint 链。
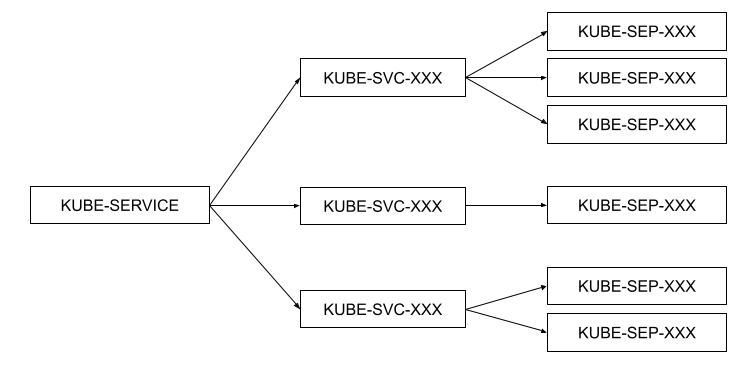
图3-9 kube-porxy 自定义链
如下命令,查看 kube-proxy 创建的规则。
$ iptables -S -t nat
-A PREROUTING -m -comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m -comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A POSTROUTING -m -comment --comment "kubernetes postrouting rules " -j KUBE-POSTROUTING
3. iptables 性能问题
Kubernetes 中 Kube-Proxy 组件有两种模式:iptables 和 IPVS。不过 iptables 的规则匹配是线性的,匹配的时间复杂度是 O(N)。规则更新是非增量式的,哪怕增加/删除一条规则,也是整体修改 iptables 规则表,当集群内 Service 数量较多,则会有较大的性能问题。而 IPVS 则专门用于高性能负载均衡,实现上使用了更高效的哈希表,时间复杂度为 O(1),性能与规模无关。
如图3-10所示,当 1000 个服务(10000 个 Pod)以上时,会开始观察到差异。
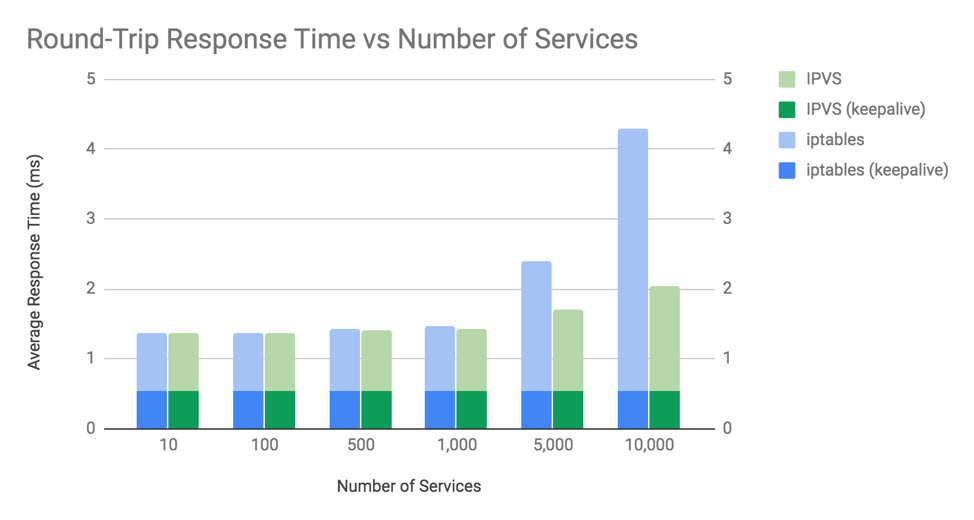
图3-10 iptables 与 IPVS 的性能差异
所以,当 Kubernetes 规模较大时,应避免使用 iptables 模式。
3.2.2 连接跟踪 conntrack
连接跟踪(connection tracking,conntrack,CT)对连接状态进行跟踪并记录。如图 3-11 所示,这是一台 IP 地址为 10.1.1.3 的 Linux 机器,我们能看到这台机器上有两条连接:
- 机器访问外部 HTTP 服务的连接(目的端口 80)。
- 机器访问外部 DNS 服务的连接(目的端口 53)。
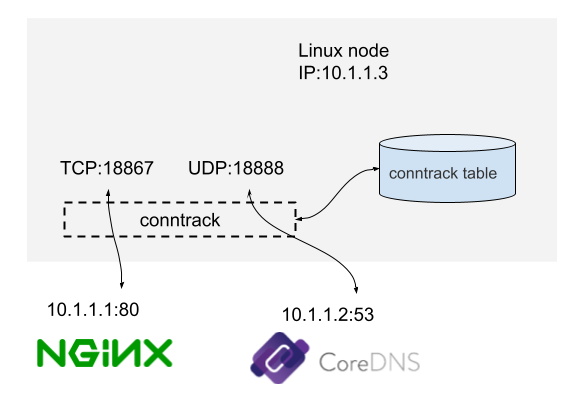
图3-11 conntrack 示例
连接跟踪所做的事情就是发现并跟踪这些连接的状态,具体包括:
- 从数据包中提取元组信息,辨别数据流和对应的连接。
- 为所有连接维护一个状态数据库(conntrack table),例如连接的创建时间、发送 包数、发送字节数等。
- 回收过期的连接(GC)。
- 为更上层的功能(例如 NAT)提供服务。
1. conntrack 原理
当加载内核模块 nf_conntrack 后,conntrack 机制就开始工作,根据图3-3《Packet flow in NetFilter and General Networking》所示,conntrack(椭圆形方框)在内核中有两处位置(PREROUTING 和 OUTPUT之前)能够跟踪数据包。
每个通过 conntrack 的数据包,内核都为其生成一个 conntrack 条目用以跟踪此连接,对于后续通过的数据包,内核会判断若此数据包属于一个已有的连接,则更新所对应的 conntrack 条目的状态(比如更新为 ESTABLISHED 状态),否则内核会为它新建一个 conntrack 条目。所有的 conntrack 条目都存放在一张表里,称为连接跟踪表(conntrack table)。
连接跟踪表存放于系统内存中,可用 cat /proc/net/nf_conntrack 命令查看当前跟踪的所有 conntrack 条目,conntrack 维护的所有信息都包含在这个条目中,通过它就可以知道某个连接处于什么状态。
如下则为表示一条状态为 ESTABLISHED 的 TCP 连接。
$ cat /proc/net/nf_conntrack ipv4 2 tcp 6 88 ESTABLISHED src=10.0.12.12 dst=10.0.12.14 sport=48318 dport=27017 src=10.0.12.14 dst=10.0.12.12 sport=27017 dport=48318 [ASSURED] mark=0 zone=0 use=2
2. conntrack 应用示例
连接跟踪是许多网络应用的基础,常用的使用场景如 NAT(Network Address Translation,网络地址转换)、iptables 的状态匹配等。
如图3-12所示,机器自己的 IP 10.1.1.3 可以与外部正常通信,但 192.168 网段是私有 IP 段,外界无法访问,源 IP 地址是 192.168 的包,其应答包也无法回来,因此:
- 当源地址为 192.168 网段的包要出去时,机器会先将源 IP 换成机器自己的 10.1.1.3 再发送出去,进行 SNAT(对源地址 source 进行 NAT)。
- 收到应答包时,再进行相反的转换,进行 DNAT(对目的地址 destination 进行 NAT)。
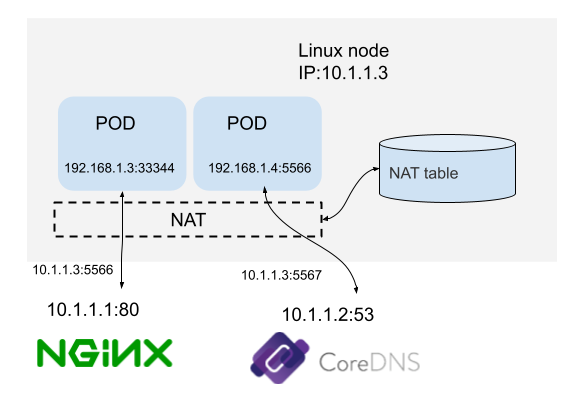
图 3-12
当 NAT 网关收到内部网络的请求包之后,会做 SNAT,同时将本次连接记录保存到连接跟踪表,当收到响应包之后,就可以根据连接跟踪表确定目的主机,然后做 DNAT,DNAT + SNAT 其实就是 Full NAT,如图3-13所示。
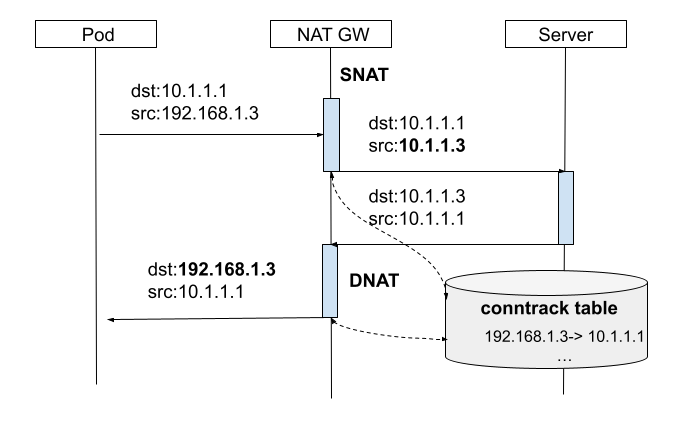
图 3-13 FullNAT
搭建 kubernetes 时有一条配置 net.bridge.bridge-nf-call-iptables = 1,很多同学不明其意,这里笔者结合 conntrack 说明这个配置的作用。
Kubernetes 的 Service 本质是个反向代理,访问 Service 时会进行 DNAT,将原本访问 ClusterIP:Port 的数据包 NAT 成 Service 的某个 Endpoint (PodIP:Port),然后内核将连接信息插入 conntrack 表以记录连接,目的端回包的时候内核从 conntrack 表匹配连接并反向 NAT,这样原路返回形成一个完整的连接链路。
但是 Linux 网桥是一个虚拟的二层转发设备,而 iptables conntrack 是在三层上,所以如果直接访问同一网桥内的地址,就会直接走二层转发,不经过 conntrack,由于没有原路返回,客户端与服务端的通信就不在一个 “频道” 上,不认为处在同一个连接,也就无法正常通信。
启用 bridge-nf-call-iptables 这个内核参数 (置为 1),表示 bridge 设备在二层转发时也去调用 iptables 配置的三层规则 (包含 conntrack),所以开启这个参数就能够解决上述 Service 同节点通信问题。
这也是为什么在 Kubernetes 环境中,大多都要求开启 bridge-nf-call-iptables 的原因。
3.2.3 快速数据路径 XDP
由于 Linux 内核协议栈更加注重通用性,所以在网络性能需求场景中存在一定的瓶颈,随着 100G、200/400G 高速率网卡的出现,这种性能瓶颈就变得无法接受了。2010 年,由 Intel 领导的 DPDK 实现了一个内核旁路(Bypass Kernel)思想的高性能网络应用开发解决方案,并逐渐成为了独树一帜的成熟技术体系。但是 DPDK 也由于内核旁路这一前提,天然就无法与内核技术生态很好的结合。
2016 年,在 Linux Netdev 会议上,David S. Miller 喊出了 “DPDK is not Linux” 的口号。同年,伴随着 eBPF 技术的成熟,Linux 内核终于迎来了属于自己的高速公路 —— XDP(AF_XDP),其具有足以媲美 DPDK 的性能以及背靠内核的多种独特优势。
以上,就是 XDP 出现的背景。
1. XDP 概述
XDP(eXpress Data Path,快速数据路径)本质上是 Linux 内核网络模块中的一个 BPF Hook,能够动态挂载 eBPF 程序逻辑,使得 Linux 内核能够在数据报文到达 L2(网卡驱动层)时就对其进行针对性高速处理处理,无需再循规蹈矩地进入到内核网络协议栈。用虚拟化领域的完全虚拟化和半虚拟化概念类比,如果 DPDK 是”完全 Kernel bypass”,那么 AF_XDP 就是 “半 Kernel bypass”。
更详细地说,AF_XDP 和 AF_INET 一样,也是 address family 的一种,AF_XDP 就相当于 socket 底层通讯方式的不同实现,AF_INET 可以用于 IPv4 类型地址的通讯,AF_XDP 则是一套基于 XDP 的通讯的实现。
XDP 程序在内核提供的网卡驱动中直接取得网卡收到的数据帧,然后直接送到用户态应用程序。应用程序利用 AF_XDP 类型的 socket 接收数据。

图 3-14 XDP 流程概念
2. XDP 应用示例
前面讲过的连接跟踪实际上独立于 Netfilter,Netfilter 只是 Linux 内核中的一种连接跟踪实现。换句话说,只要具备了 hook 能力,能拦截到进出主机的每个数据包,就完全可以在此基础上实现另外一套连接跟踪。
云原生网络方案 Cilium 在 1.7.4+ 版本就实现了这样一套独立的连接跟踪和 NAT 机制,其基本原理是:
- 基于 BPF hook 实现数据包的拦截功能(等价于 netfilter 的 hook 机制)
- 在 BPF hook 的基础上,实现一套全新的 conntrack 和 NAT
因此使用 Cilium 方案的 Kubernetes 网络模型,即便在 Node 节点卸载 Netfilter,也不会影响 Cilium 对 Kubernetes ClusterIP、NodePort、ExternalIPs 和 LoadBalancer 等功能的支持。

图 3-15 conntrack Cilium 方案
由于 Cilium 方案的连接跟踪机制独立于 Netfilter,因此它的 conntrack 和 NAT 信息也没有存储在内核中的 conntrack table 和 NAT table 中,常规的 conntrack/netstats/ss/lsof 等工具看不到 nat、conntrack 数据,所以需要另外使用 Cilium 的命令查询,例如:
$ cilium bpf nat list
$ cilium bpf ct list global
添加评论