-
由
 虚拟的现实创建于10月 13, 2023
需要 1 分钟阅读时间
虚拟的现实创建于10月 13, 2023
需要 1 分钟阅读时间
简介
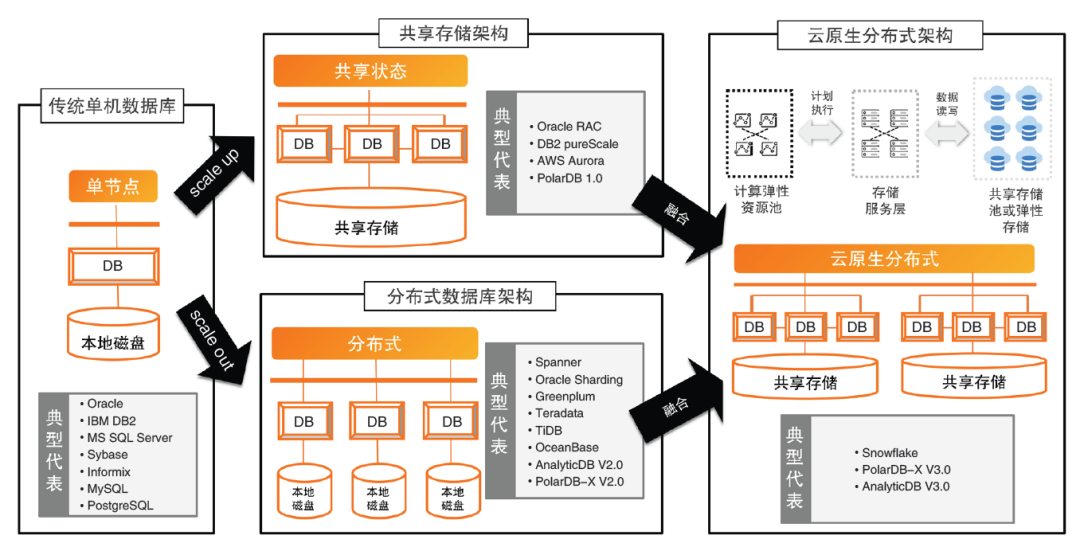
这张图来自于李飞飞的一片文章,介绍了数据库的过去和未来。
不同的数据类型
单机数据库
经常听到说传统单机数据库是一种shared-everything的架构,怎么理解呢?
实际上这里的 everything 指的是冯·诺依曼架构中的「计算」和「存储」,而 shared 指的是单机数据库可以随意使用本地的所有「计算」和「存储」资源。
分布式数据库
很快,单机数据库就面临着可扩展性问题,这时就需要通过加资源的方式解决,于是出现了两种解决方案:Scale up 和 Scale out。
这里 Scale up 并不是指单机维度的 scale up,而是从资源视角的 scale up。
更具体地说,也就是存储池化:数据库的底层存储由原来的单机磁盘(磁盘阵列)、单机文件系统,演变为基于分布式块存储、分布式文件存储、对象存储等的 shared-storage 分布式数据库。
Scale out 则是各个数据库实例独立运行,实例之间通过 raft/paxos 等共识算法实现数据同步,而不依赖底层的分布式存储系统。
这就是所谓的 shared-nothing 分布式数据库,数据库不共享任何 IaaS 层的资源,完全依赖于 PaaS 层(DB)本身,去做高可用和强一致,实现分布式事务。
云原生数据库
云原生数据库 = 分布式数据库(scale out) + 资源池化(scale up)。
云原生 = 云 + 原生。「云」就代表着IaaS资源池化,「原生」意味着应用(PaaS、SaaS)天然就是针对这种池化的特性进行设计的。
现在的分布式数据库大多是 shared-nothing 的,例如 tidb 和 ob,使用了本地盘。
一旦使用本地盘,就意味着无法上云,因为云的特性就是资源池化,所以要上云,就要使用公有云厂商提供的EBS、S3等云盘。
而云盘的性能没有本地盘好,这就要求应用层,也就是DB这一层,是面向公有云的基础服务进行设计的。
这就是云原生的数据库,即在数据库设计的时候,就考虑各种资源是在云上,以池化的方式提供。
这种方式意味着 shared-nothing 和 shared-everything 的结合:宏观上看,是 shared-everything 的(未来内存也会池化),从微观上看,又是分布式的shared-nothing。
这是一种真正的算存分离:在单机部署情况下,通信就是计算通过 Memory Bus、IO Bus和内存、存储通信。
但在集群部署的情况下,计算和存储的通信就是网络。数据库刚诞生的年代,单机的存储访问速度肯定要快于集群,但是随着网络、存储等基础设施的不断发展,未来这个情况可能就不一定了,IaaS池化一定是未来,云计算一定是未来,数据库上云一定是未来。
存在的问题
分布式数据库上k8s会遇到哪些问题呢?
由于分布式数据库在设计上就不是云原生的,一般比较适合 on-primises 部署,也就是直接部署在物理机上,而不是部署到云上。
由于使用本地盘,分布式数据库不适合通过 k8s 进行部署。
但是,随着基础设施硬件的不断发展,池化后的资源不会再成为性能瓶颈,所以云原生数据库一定是数据库的未来,现在的分布式数据库也在往云原生数据库的方向演进,到那一天,有状态应用就可以在k8s上发挥它最大的威力。
本地盘
本地盘使用的是静态PV,不支持动态 scale up,灵活性差。
cgroup v1的IO隔离机制有缺陷,无法对buffered IO的IOPS进行很好的限制。
本地盘在做节点迁移时,需要迁移数据。众所周知移动计算比移动数据更方便。
没法利用k8s的自我修复能力。比如节点挂了,你可以通过起一个新的Pod的方式进行修复。但是如果用了本地盘,这个Pod却必须调度到原节点。
网盘
在公有云上,使用网盘最大的问题第一是延迟抖动;第二是性能比本地盘要差很多。如何在软件层面克服这种问题是云原生数据库要攻克的难关。
现有的云原生数据库(比如snowflake)一般都是面向OLAP的数据仓库,原因在于数据仓库对于吞吐的要求其实是更高的,对于延迟并不是那么在意,一个 query 可能跑五秒出结果就行了,不用要求五毫秒之内给出结果。
特别是对于一些 Point Lookup 这种场景来说,Shared Nothing 的 database 可能只需要从客户端的一次 rpc,但是对于计算与存储分离的架构,中间无论如何要走两次网络,这是一个核心的问题。
Aurora 是一个计算存储分离架构,但它是一个单机数据库,Spanner 是一个纯分布式的数据库,纯 Shared Nothing 的架构并没有利用到云基础设施提供的一些优势。
0 评论