Kubernetes 基础教程
在当今数字化时代,Kubernetes 已经成为云原生技术的核心引擎,为应用程序的构建、部署和扩展提供了无与伦比的灵活性和可靠性。对于想要掌握现代容器编排技术的开发者和运维人员来说,深入理解
Kubernetes 是一项必不可少的技能。本教程致力于为初学者提供全面而深入的 Kubernetes 学习体验,无论您是刚刚踏入云原生领域,还是寻求巩固知识并进一步提升技能水平。
环境准备:
10.0.2.2 k8s-master
10.0.2.3 k8s-node1
可参考下面的教程来搭建Kubernetes多节点集群:
一些提高效率的设置:
- 安装ohmyzsh
- 设置kubectl的alias为
kk,下文会用到。
1. 简介
Kubernetes 的名字来自古希腊语,意思是“飞行员”或“舵手”(掌舵的人),其历史通常可以追溯到2013年,当时谷歌的三位工程师Craig
McLuckie,Joe Beda和Brendan
Burns提出了一个构建开源容器管理系统的想法。这些技术先驱正在寻找将谷歌内部基础设施专业知识引入大规模云计算领域的方法,并使谷歌能够与当时云提供商中无与伦比的领导者亚马逊网络服务(AWS)竞争。
Kubernetes
项目是Google公司在2014年正式启动(受到Google在2003年使用C++编写开发并使用十年之久的内部项目Borg的积极影响)。它建立在Google公司超过10多年的运维经验之上,Google所有的应用都运行在容器上。
Kubernetes是目前最受欢迎的开源容器编排平台。
所谓编排(orchestrator),即对资源进行分配、调度、调优等操作。如果将Kubernetes比做是一个足球教练,
那它对集群内各类资源的编排操作可以简单理解为教练对球员们的指导操作(包括位置分配、战术指挥以及场上突发状况处理等)。
它们有一个共同目标就是让集群内所有资源(球员)协同工作,发挥出最大的效能。
Kubernetes v1.0于2015年7月21日发布。随着v1.0版本发布,谷歌与Linux基金会合作组建了Cloud
Native Computing
Foundation(CNCF)并将 Kubernetes 作为种子项目来孵化。项目开源伊始,众多国际大厂如微软、IBM、红帽、Docker、Mesosphere、CoreOS和SaltStack纷纷加入并表示将积极支持该项目。
CNCF由世界领先的计算公司的众多成员共同创建,包括Docker,Google,Microsoft,IBM和Red
Hat。CNCF的使命是“让云原生计算无处不在”。
Kubernetes 可以实现容器集群的自动化部署、自动扩缩容、维护等功能。它拥有自动包装、自我修复、横向缩放、服务发现、负载均衡、
自动部署、升级回滚、存储编排等特性。
Kubernetes 开源已近十年时间,已有颇多荣誉和光荣事迹。这里进行简单罗列:
- 2015年作为CNCF的第一个种子项目进行孵化,2016年正式托管,并于2018年成为CNCF的第一个毕业项目。
- 2016 年 Q2-Q3: 以 Mirantis 为首的 OpenStack 厂商积极推动与 Kubernetes 的整合,避免站在 Kubernetes 的对立面,成为被
Kubernetes 推翻的“老一代技术”。 - 2016 年 12 月,伴随着 Kubernetes 1.5 的发布,Windows Server 和 Windows 容器可以正式支持 Kubernetes,微软生态完美融入。
- 2017 年 2 月,Kubernetes 官方微博报道了中国京东用 Kubernetes 替代了 OpenStack 中的大量服务和组件,实现全容器化私有云和公有云的建设,中国的
Kubernetes 用户案例首次登上国际舞台。 - 2017 年 6 月,在北京召开的 LinuxCon 上,中国公司报道了 Kubernetes 在中国金融、电力、互联网行业的成功案例,标志着 Kubernetes
的终端用户群体走向国际化。 - 2017年,Kubernetes 超越了Docker Swarm和Apache Mesos等竞争对手,成为容器编排行业的事实标准。
- 同样在2017这一年里,主要竞争对手们Docker、VMWare、Mesos、Microsoft、AWS都围绕Kubernetes团结起来,宣布为其添加本地支持
- 2 岁生日之际,Kubernetes 的用户涵盖了诸如金融(摩根斯坦利、高盛)、互联网(eBay、Box、GitHub)、传媒(Pearson、New York Times)
、通信(三星、华为)等行业的龙头企业。 - 2018年3月6日,Kubernetes项目在GitHub项目列表中的提交数量排名第九,作者和问题排名第二,仅次于Linux内核。
ACK等。 - 从CNCF创立至今, Kubernetes 一直都是其顶级项目,同时也是Go语言的成名开源项目之一(其他有Docker/Prometheus/etcd等)。CNCF管理下的大部分项目也都是围绕Kubernetes
生态建立的。
截至今日(2023年底),Kubernetes
项目的代码贡献者就多达3500+人,Star数高达10.4w(总排名第40位)。除了主体代码库之外,还有约
60 个其他的插件代码库。
现今信息界常见的缩写手法“K8s”则是将“ubernete”八个字母缩写为“8”而来。
多云提供商支持
Kubernetes 被广泛地支持和集成到各大云服务提供商的容器服务中,包括Google Kubernetes Engine(GKE)、Amazon
Elastic Kubernetes Service(EKS)、Microsoft Azure Kubernetes Service(AKS)等,国内有腾讯云 TKE和阿里云 ACK等。
1.1 架构设计
K8s集群节点拥有Master和Node两种角色。它们的职责如下:
- Master:官方叫做控制平面(Control
Plane)。主要负责整个集群的管控,包含监控、编排、调度集群中的各类资源对象(如Pod/Deployment等)。
通常Master会占用一个单独的集群节点(不会运行应用容器),基于高可用可能会占用多台,参考kubeadm搭建高可用集群。
(提供K8s集群托管的云厂商也会为你的集群主节点提供高可用部署) - Node:数据平面。是集群中的承载实际工作任务的节点,直接负责对容器资源的控制,可以无限扩展。
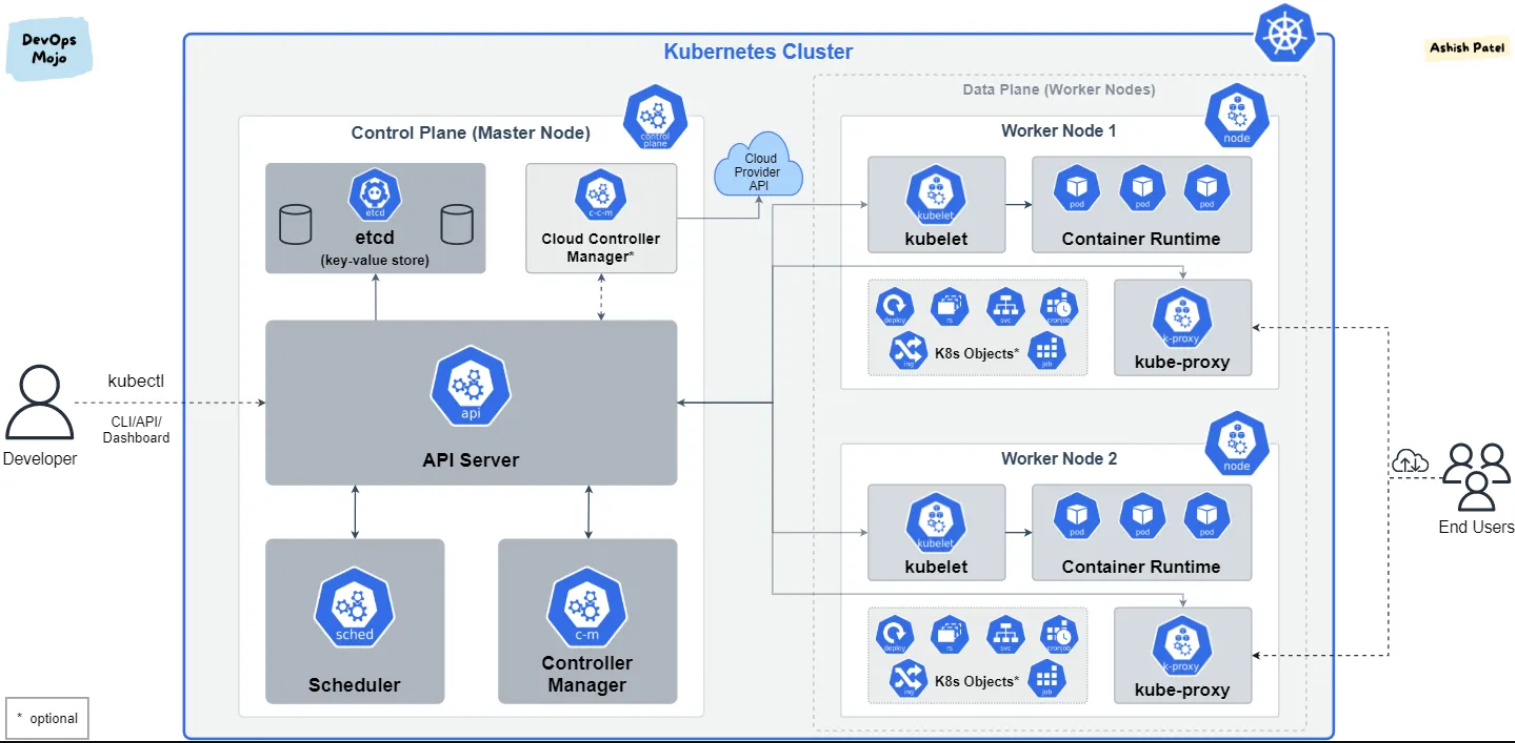
1.2 Master
Master由四个部分组成:
- API Server进程
核心组件之一,为集群中各类资源提供增删改查的HTTP REST接口,即操作任何资源都要经过API Server。Master上kube-system
空间中运行的Pod之一kube-apiserver是API
Server的具体实现。与其通信有三种方式:
- 最原始的通过REST API访问;
- 通过官方提供的Client来访问,本质上也是REST API调用;
- 通过kubectl客户端访问,其本质上是将命令转换为REST API调用,是最主要的访问方式。
-
etcd
K8s使用etcd作为内部数据库,用于保存集群配置以及所有对象的状态信息。只有API Server进程能直接读写etcd。为了保证集群数据安全性,建议为其考虑备份方案。
如果etcd不可用,应用容器仍然会继续运行,但用户无法对集群做任何操作(包括对任何资源的增删改查)。 -
调度器(Scheduler)
它是Pod资源的调度器,用于监听刚创建还未分配Node的Pod,为其分配相应Node。
调度时会考虑资源需求、硬件/软件/指定限制条件以及内部负载情况等因素,所以可能会调度失败。
调度器也是操作API Server进程的各项接口来完成调度的。比如Watch接口监听新建的Pod,并搜索所有满足Pod需求的Node列表,
再执行Pod调度逻辑,调度成功后将Pod绑定到目标Node上。 -
控制器管理器(kube-controller-manager)
Controller管理器实现了全部的后台控制循环,完成对集群的健康并对事件做出响应。Controller管理器是各种Controller的管理者,负责创建controller,并监控它们的执行。
这些Controller包括NodeController、ReplicationController等,每个controller都在后台启动了一个独立的监听循环(可以简单理解为一个线程),负责监控API
Server的变更。
- Node控制器:负责管理和维护集群中的节点。比如节点的健康检查、注册/注销、节点状态报告、自动扩容等。
- Replication控制器:确保集群中运行的 Pod 的数量与指定的副本数(replica)保持一致,稍微具体的说,对于每一个Replication控制器管理下的Pod组,具有以下逻辑:
- 当Pod组中的任何一个Pod被删除或故障时,Replication控制器会自动创建新的Pod来作为替代
- 当Pod组内的Pod数量超过所定义的
replica数量时,Replication控制器会终止多余的Pod
- Endpoint控制器:负责生成和维护所有Endpoint对象的控制器。Endpoint控制器用于监听Service和对应Pod副本的变化
- ServiceAccount及Token控制器:为新的命名空间创建默认账户和API访问令牌。
- 等等。
kube-controller-manager所执行的各项操作也是基于API Server进程的。
1.3 Node
Node由三部分组成:kubelet、kube-proxy和容器运行时(如docker/containerd)。
- kubelet
它是每个Node上都运行的主要代理进程。kubelet以PodSpec为单位来运行任务,后者是一种Pod的yaml或json对象。
kubelet会运行由各种方式提供的一系列PodSpec,并确保这些PodSpec描述的容器健康运行。
不是k8s创建的容器不属于kubelet管理范围,kubelet也会及时将Pod内容器状态报告给API Server,并定期执行PodSpec描述的容器健康检查。
同时kubelet也负责存储卷等资源的管理。
kubelet会定期调用Master节点上的API Server的REST API以报告自身状态,然后由API Server存储到etcd中。
-
kube-proxy
每个节点都会运行一个kube-proxy Pod。它作为K8s Service的网络访问入口,负责将Service的流量转发到后端的Pod,并提供Service的负载均衡能力。
kube-proxy会监听 API Server 中 Service 和 Endpoint 资源的变化,并将这些变化实时反应到节点的网络规则中,确保流量正确路由到服务。
总结来说,kube-proxy主要负责维护网络规则和四层流量的负载均衡工作。 -
容器运行时
负责直接管理容器生命周期的软件。k8s支持包含docker、containerd在内的任何基于k8s cri(容器运行时接口)实现的runtime。
1.4 K8s的核心对象
为了完成对大规模容器集群的高效率、全功能性的任务编排,k8s设计了一系列额外的抽象层,这些抽象层对应的实例由用户通过Yaml或Json文件进行描述,
然后由k8s的API Server负责解析、存储和维护。
k8s的对象模型图如下:
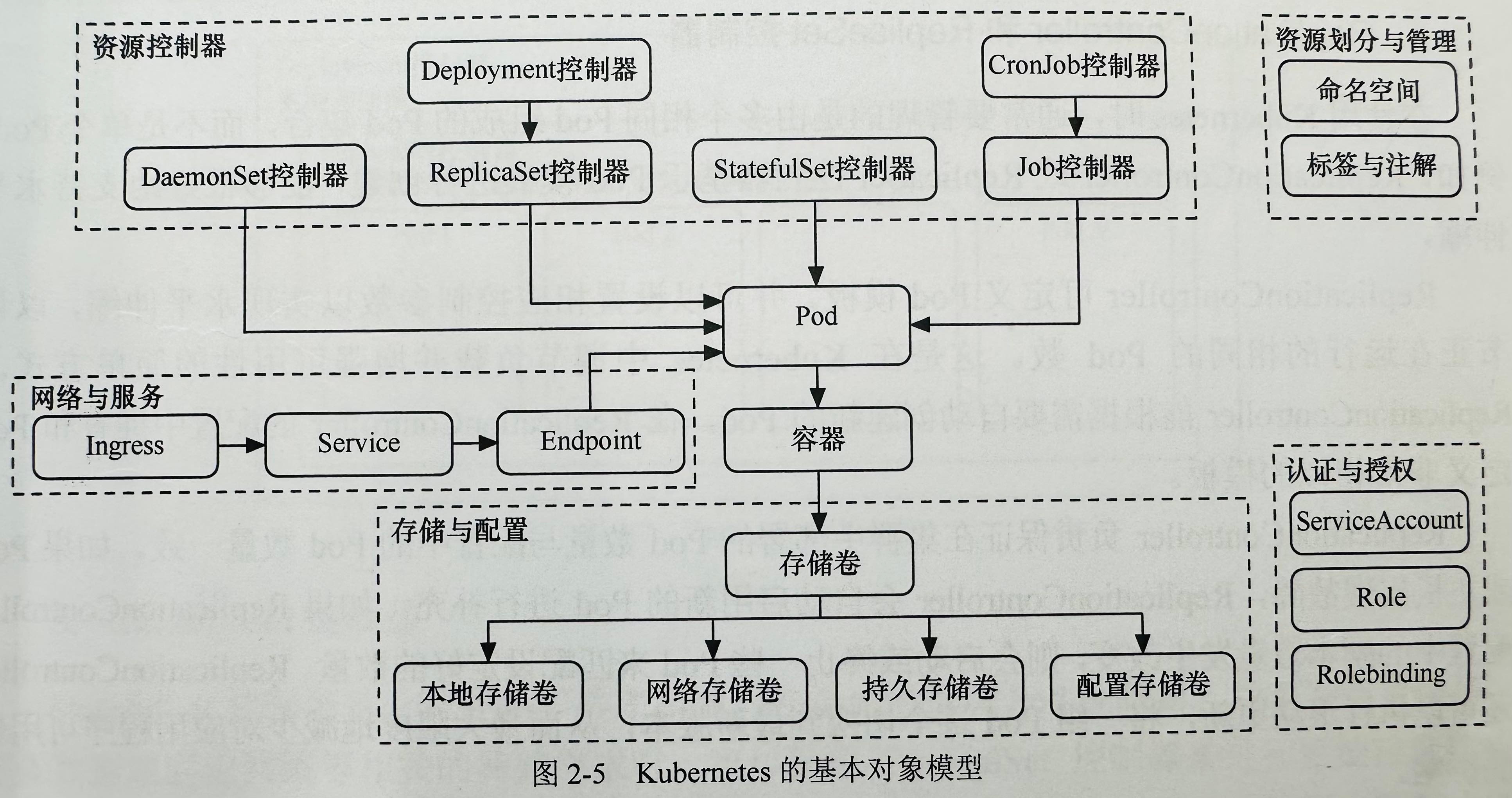
- Pod
Pod是k8s调度的基本单元,它封装了一个或多个容器。Pod中的容器会作为一个整体被k8s调度到一个Node上运行。
Pod一般代表单个app,由一个或多个关系紧密的容器组成。这些容器拥有共同的生命周期,作为一个整体被编排到Node上。并且它们
共享存储卷、网络和计算资源。k8s以Pod为最小单位进行调度等操作。
- 控制器
一般来说,用户不会直接创建Pod,而是创建控制器来管理Pod,因为控制器能够更细粒度的控制Pod的运行方式,比如副本数量、部署位置等。
控制器包含下面几种:
- Replication控制器(以及ReplicaSet控制器):负责保证Pod副本数量符合预期(涉及对Pod的启动、停止等操作);
- Deployment控制器:是高于Replication控制器的对象,也是最常用的控制器,用于管理Pod的发布、更新、回滚等;
- StatefulSet控制器:与Deployment同级,提供排序和唯一性保证的特殊Pod控制器。用于管理有状态服务,比如数据库等。
- DaemonSet控制器:与Deployment同级,用于在集群中的每个Node上运行单个Pod,多用于日志收集和转发、监控等功能的服务。并且它可以绕过常规Pod无法调度到Master运行的限制;
- Job控制器:与Deployment同级,用于管理一次性任务,比如批处理任务;
- CronJob控制器:与Deployment同级,在Job控制器基础上增加了时间调度,用于执行定时任务。
- Service、Ingress和Storage
Service是对一组Pod的抽象,它定义了Pod的逻辑集合以及访问该集合的策略。前面的Deployment等控制器只定义了Pod运行数量和生命周期,
并没有定义如何访问这些Pod,由于Pod重启后IP会发生变化,没有固定IP和端口提供服务。
Service对象就是为了解决这个问题。Service可以自动跟踪并绑定后端控制器管理的多个Pod,即使发生重启、扩容等事件也能自动处理,
同时提供统一IP供前端访问,所以通过Service就可以获得服务发现的能力,部署微服务时就无需单独部署注册中心组件。
Ingress不是一种服务类型,而是一个路由规则集合,通过Ingress规则定义的规则,可以将多个Service组合成一个虚拟服务(如前端页面+后端API)。
它可实现业务网关的作用,类似Nginx的用法,可以实现负载均衡、SSL卸载、流量转发、流量控制等功能。
Storage是Pod中用于存储的抽象,它定义了Pod的存储卷,包括本地存储和网络存储;它的生命周期独立于Pod之外,可进行单独控制。
- 资源划分
- 命名空间(Namespace):k8s通过namespace对同一台物理机上的k8s资源进行逻辑隔离。
- 标签(Labels):是一种语义化标记,可以附加到Pod、Node等对象之上,然后更高级的对象可以基于标签对它们进行筛选和调用,
例如Service可以将请求只路由到指定标签的Pod,或者Deployment可以将Pod只调度到指定标签的Node。 -
注解(Annotations):也是键值对数据,但更灵活,它的value允许包含结构化数据。一般用于元数据配置,不用于筛选。
例如Ingress中通过注解为nginx控制器配置禁用ssl重定向。
1.5 在K8s上运行应用的流程
- 将某种编程语言所构建的应用打包为镜像
- 将该应用需要的镜像版本、对外暴露端口号和所需CPU、内存等需求定义到K8s Pod模板(术语:PodSpec,模板文件称为Manifest)
- 部署Pod模板并观察运行状态
- 调整模板配置以适应新的需求
如果应用需要故障自愈等高级功能,则使用更高级的控制器如Deployment、DaemonSet等定义Pod模板即可。
1.6 K8s DNS
每个K8s集群都有自己独立的DNS服务,用于为集群中的Pod提供域名解析服务。集群DNS服务有一个静态IP,每个新启动的Pod内部都会在/etc/resolve.conf
中硬编码这个IP作为DNS服务器。
每当新的Service被发布到集群中的时候,同时也会在集群DNS服务中创建一个域名记录(对应其后端Pod
IP),这样Pod就可以通过Service的域名访问其对应的服务。一些比较特殊的Pod也会注册到集群DNS服务器,
比如StatefulSet管理下的每个Pod(以PodName-0-*, PodName-1-*的形式)。
集群的DNS服务器由集群内一个名为kube-dns的Service提供,它将DNS请求均衡转发到每个节点上的coredns-*Pod。
集群DNS服务使用CoreDNS作为后端,CoreDNS是一个由Go实现的高性能且灵活的DNS Server,支持使用自定义插件来扩展功能。
2. 创建程序和使用docker管理镜像
2.1 安装docker
如果安装的K8s版本不使用Docker作为容器运行时,则不需要在任何K8s节点上安装Docker。但为了方便测试,笔者选择在master节点安装docker以便构建和推送镜像到仓库。
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 列出可用版本
#yum list docker-ce --showduplicates | sort -r
# 选择版本安装
yum -y install docker-ce-18.03.1.ce
docker version
# 设置源
echo '{
"registry-mirrors": [
"https://registry.docker-cn.com"
]
}' > /etc/docker/daemon.json
# 重启docker
systemctl restart docker
# 开机启动
systemctl enable docker
# 查看源是否设置成功
$ docker info |grep Mirrors -A 3
Registry Mirrors:
https://registry.docker-cn.com/
另外,可能需要纠正主机时间和时区:
# 先设置时区 echo "ZONE=Asia/Shanghai" >> /etc/sysconfig/clock ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime # 若时间不准,则同步时间(容器会使用节点的时间) yum -y install ntpdate ntpdate -u pool.ntp.org $ date # 检查时间
2.2 构建和运行镜像
- 编写一个简单的main.go
- 编写Dockerfile
打包镜像(替换leigg为你的docker账户名)
docker build . -t leigg/hellok8s:v1
这里有个小技巧,(修改代码后)重新构建镜像若使用同样的镜像名会导致旧的镜像的名称和tag变成<none>,可通过下面的命令来一键删除:
docker image prune -f # docker system prune # 删除未使用的容器/网络等资源
测试运行:
docker run --rm -p 3000:3000 leigg/hellok8s:v1
运行ok则按ctrl+c退出。
2.3. 推送到docker仓库
k8s部署服务时会从远端拉取本地不存在的镜像,但由于这个k8s版本是使用containerd不是docker作为容器运行时,
所以读取不到docker构建的本地镜像,另外即使当前节点有本地镜像,其他节点不存在也会从远端拉取,所以每次修改代码后,
都需要推送新的镜像到远端,再更新部署。
先登录docker hub:
$ docker login # 然后输入自己的docker账户和密码,没有先去官网注册
推送镜像到远程hub
docker push leigg/hellok8s:v1
如果是生产部署,则不会使用docker官方仓库,而是使用harbor等项目搭建本地仓库,以保证稳定拉取镜像。
3. 使用Pod
在VMware的世界中,调度的原子单位是虚拟机(VM);在Docker的世界中,调度的原子单位是容器(Container);而在
Kubernetes的世界中,调度的原子单位是Pod。 ——Nigel Poulton
Pod术语的起源:在英语中,会将a group of whales(一群鲸鱼) 称作a Pod of whales
,Pod就是来源于此。因为Docker的Logo是鲸鱼拖着一堆集装箱(表示Docker托管一个个容器),
所以在K8s中,Pod就是一组容器的集合。———参考自 Kubernetes 修炼手册
K8s当然支持容器化应用,但是,用户无法直接在集群中运行一个容器,而是需要将容器定义在Pod中来运行。
Pod 是 Kubernetes 中最小的可部署和调度单元,通常包含一个或多个容器。这些紧密耦合容器共享名字空间和文件系统卷,类似运行在同一主机上的应用程序和其辅助进程。
Pod有两种运行方式。一种是单独运行(叫做单例),这种方式运行的Pod没有自愈能力,一旦因为各种原因被删除就不会再重新创建。
另一种则是常见的在控制器管理下运行,控制器会持续监控Pod副本数量是否符合预期,并在Pod异常时重新创建新的Pod进行替换。
在阅读完本章节后,你可以在 example_pod 目录下查看更多Pod模板示例。
3.1 定义、创建和删除Pod
k8s中的各种资源对象基本都是由yaml文件定义,Pod也不例外。下面是使用nginx最新版本的单例Pod模板:
# nginx.yaml
apiVersion: v1
kind: Pod # 资源类型=pod
metadata:
name: nginx-pod # 需要在当前命名空间中唯一
namespace: default # 默认是default,可省略
spec:
containers: # pod内的容器组
- name: nginx-container
image: nginx # 镜像默认来源 DockerHub
运行第一条k8s命令创建pod:
kk apply -f nginx.yaml
查看nginx-pod状态:
kk get pod nginx-pod
查看全部pods:
kk get pods
命令中的pods可以简写为po。
如果要删除Pod,可以执行:
kk delete pod nginx-pod
3.2 修改Pod
在创建Pod后,我们可能会修改Pod的部分配置,比如修改镜像版本,修改容器启动参数等。修改方式有两种:
- 直接修改yaml文件然后再次apply即可
- 通过patch命令修改
第一种方式比较简单,就不再演示。这里演示第二种方式:
$ kk patch pod nginx-pod -p '{"spec":{"containers":[{"name":"nginx-container","image":"nginx:1.10.1"}]}}'
pod/nginx-pod patched
$ kk describe po nginx-pod |grep Image
Image: nginx:1.10.1
Image ID: docker.io/library/nginx@sha256:35779791c05d119df4fe476db8f47c0bee5943c83eba5656a15fc046db48178b
注意:修改容器配置会触发Pod内的容器重启,Pod本身不会完全重启。
一般是使用第一种方式,第二种方式由于参数复杂仅用于某些时候的临时修改。此外,PodSpec中的大部分参数是创建后不可修改的,例如在尝试修改Pod网络时会得到以下提示:
$ kk apply -f nginx.yaml
The Pod "nginx-pod" is invalid: spec: Forbidden: pod updates may not change fields other than
`spec.containers[*].image`, `spec.initContainers[*].image`, `spec.activeDeadlineSeconds`,
`spec.tolerations` (only additions to existing tolerations) or
`spec.terminationGracePeriodSeconds` (allow it to be set to 1 if it was previously negative)
...
可见允许修改的有镜像相关、activeDeadlineSeconds、tolerations和terminationGracePeriodSeconds这几个字段。
如果想要修改其他字段,只能在删除Pod后重新创建。
3.3 与Pod交互
添加端口转发,然后就可以在宿主机访问nginx-pod
# 宿主机4000映射到pod的80端口 # 这条命令是阻塞的,仅用来调试pod服务是否正常运行 kk port-forward nginx-pod 4000:80 # 打开另一个控制台 curl http://127.0.0.1:4000
进入Pod Shell:
kk exec -it nginx-pod -- /bin/bash # 当Pod内存在多个容器时,通过-c指定进入哪个容器 kk exec -it nginx-pod -c nginx-container -- /bin/bash
其他Pod常用命令:
kk delete pod nginx-pod # 删除pod kk delete -f nginx.yaml # 删除配置文件内的全部资源 kk logs -f nginx-pod # 查看日志(stdout/stderr),支持 --tail <lines> kk logs -f nginx-pod -c container-2 # 指定查看某个容器的日志
3.4 Pod与Container的不同
在刚刚创建的资源里,在最内层是我们的服务 nginx,运行在 Container 当中, Container (容器) 的本质是进程,而 Pod
是管理这一组进程的资源。
Sidecar模式
Pod 可以管理多个 Container。例如在某些场景服务之间需要文件交换(日志收集),本地网络通信需求(使用 localhost 或者 Socket
文件进行本地通信),这时候就会部署多容器Pod。
这是一种常见的容器设计模式,它有个名称叫做Sidecar。Sidecar模式中主要包含两类容器,一类是主应用容器,另一类是辅助容器(称为
sidecar 容器)提供额外的功能,它们共享相同的网络和存储空间。这个模式的灵感来自于摩托车上的辅助座位,因此得名 “Sidecar”。
3.5 Init容器
Init 容器是一种特殊容器,在 Pod 内的应用容器启动之前运行。Init 容器可以包括一些应用镜像中不存在的实用工具和安装脚本。
Init容器有一些特点如下:
- 允许定义一个或多个Init容器
- 它们会先于Pod内其他普通容器启动
- 它们总会在运行短暂时间后进入
Completed状态 - 它们会严格按照定义的顺序启动,每个容器成功运行结束后才会启动下一个
- 任意一个Init容器运行失败都会导致Pod进入异常状态,这会引起Pod重启,除非PodSpec中设置的
restartPolicy策略为Never - 当Init容器正常终止时(exitCode=0),即使PodSpec中设置的
restartPolicy策略为Always,Pod也不会重启 - 修改Init容器的镜像会导致Pod重启
- Init 容器支持普通容器的全部字段和特性,除了
lifecycle、livenessProbe、readinessProbe 和 startupProbe - Pod 重启会导致 Init 容器重新执行
Init 容器具有与应用容器分离的单独镜像,我们可以使用它来完成一些常规的脚本任务,比如需要sed、awk、python 或 dig
这样的工具完成的任务,而没必要在应用容器中去安装这些命令。
说明:包含常用工具的镜像有busybox,appropriate/curl等。
pod_initContainer.yaml 是一个简单的例子,这个模板中定义了两个Init容器,
分别的任务是持续等待一个Service启动,等待期间会打印消息,当各自等待的Service都启动后,两个Init容器会自动退出,然后再启动普通容器。
3.6 创建Go程序的Pod
定义pod.yaml,这里面使用了之前已经推送的镜像leigg/hellok8s:v1
创建Pod:
$ kk apply -f pod.yaml # 几秒后 $ kk get pods NAME READY STATUS RESTARTS AGE go-http 1/1 Running 0 17s
临时开启端口转发(在master节点):
# 绑定pod端口3000到master节点的3000端口 kk port-forward go-http 3000:3000
现在pod提供的http服务可以在master节点上可用。
打开另一个会话测试:
$ curl http://localhost:3000 [v1] Hello, Kubernetes!#
3.7 Pod的生命周期
通过kk get po看到的STATUS字段存在以下情况:
- Pending(挂起): Pod 正在调度中(主要是节点选择)。
- ContainerCreating(容器创建中): Pod 已经被调度,但其中的容器尚未完全创建和启动(包含镜像拉取)。
- Running(运行中): Pod 中的容器已经在运行。
- Terminating(正在终止): 删除或重启Pod会使其进入此状态,Pod默认有一个终止宽限时间是30s,可以在模板中修改(Pod可能由于某些原因会一直停留在此状态)。
- Succeeded(已成功终止): 所有容器都成功终止,任务或工作完成,特指那些一次性或批处理任务而不是常驻容器。
- Failed(已失败): 至少一个容器以非零退出码终止。
- Unknown(未知): 无法获取 Pod 的状态,通常是与Pod所在节点通信失败导致。
关于Pod的重启策略
即spec.restartPolicy字段,可选值为Always/OnFailure/Never。此策略对Pod内所有容器有效,
由Pod所在Node上的kubelet执行判断和重启。由kubelet重启的已退出容器将会以递增延迟的方式(10s,20s,40s…)
尝试重启,上限5min。成功运行10min后这个时间会重置。一旦Pod绑定到某个节点上,除非节点自身问题或手动调整,
否则不会再调度到其他节点。
Pod的销毁过程
当Pod需要销毁时,kubelet会先向API Server发送删除请求,然后等待Pod中所有容器停止,包含以下过程:
- 用户发送Pod删除命令
- API Server更新Pod:开始销毁,并设定宽限时间(默认30s,可通过–grace-period=n指定,为0时需要追加–force),超时强制Kill
- 同时触发:
- Pod 标记为 Terminating
- kubelet监听到 Terminating 状态,开始终止Pod
- Endpoint控制器监控到Pod即将删除,将移除所有Service对象中与此Pod关联的Endpoint对象
- 如Pod定义了prepStop回调,则会在Pod中执行,并再次执行步骤2,且增加宽限时间2s
- Pod进程收到SIGTERM信号
- 到达宽限时间还在运行,kubelet发送SIGKILL信号,设置宽限时间0s,直接删除Pod
尽管可以指定--force参数,但有些Pod可能处于某种异常状态仍然不能从节点上被彻底删除,
即使你通过kubectl get po
看不到对应的Pod。这对于StatefulSet类型的应用可能是灾难性的,通过 强制删除 StatefulSet 中的 Pod
了解更多细节。
Pod的生命期
Pod是临时性的一次性实体,Pod的调度过程就是将Pod调度到某个节点的过程。Pod创建后获得一个唯一的UID。
Pod一般只会被调度一次,如果所在节点失效或因为节点资源耗尽等原因驱逐节点上的部分或全部Pod,则这些Pod会在短暂时间后被删除。Pod本身不具有自愈能力,
所以如果Pod是单实例而不是由控制器管理的话,一旦Pod被删除就不会再被重建。由控制器管理的Pod会被重建,它们的名称(主要部分)不会变化,但会获得一个新的UID。
容器状态
一旦调度器将 Pod 分派给某个节点,kubelet 就通过容器运行时开始为 Pod 创建容器。容器的状态有三种:Waiting(等待)、Running(运行中)和
Terminated(已终止)。
你可以使用 kubectl describe pod <pod 名称>来检查每个容器的状态(输出中的Containers.State)。
3.8 Pod与控制器
在生产环境中,我们很少会直接部署一个单实例Pod。因为Pod被设计为一种临时性的一次性实体,当因为人为或资源不足等情况被删除时,Pod不会自动恢复。
但是当我们使用控制器来创建Pod时,Pod的生命周期就会受到控制器管理。这种管理具体表现为Pod将拥有横向扩展以及故障自愈的能力。
常见的控制器类型如下:
- Deployment
- StatefulSet
- DaemonSet
- Job/CronJob
下文将进一步介绍这些控制器。
3.9 Pod联网
每个Pod能够获得一个独立的IP地址,Pod中的容器共享网络命名空间,包括IP地址和网络端口。Pod 内的容器可以使用 localhost
互相通信,它们也能通过如 SystemV 信号量或 POSIX 共享内存这类标准的进程间通信方式互相通信。Pod间通信或Pod对外暴露服务需要使用
Service 资源,这将在后面的章节中提到。
Pod默认可以访问外部网络。
Pod 中的容器所看到的系统主机名与为Pod名称相同。
4. 使用Deployment
通常,Pod不会被直接创建和管理,而是由更高级别的控制器,例如Deployment来创建和管理。
这是因为控制器提供了更强大的应用程序管理功能。
-
应用管理:Deployment是Kubernetes中的一个控制器,用于管理应用程序的部署和更新。它允许你定义应用程序的期望状态,然后确保集群中的副本数符合这个状态。
-
自愈能力:Deployment可以自动修复故障,如果Pod失败,它将启动新的Pod来替代。这有助于确保应用程序的高可用性。
-
滚动更新:Deployment支持滚动更新,允许你逐步将新版本的应用程序部署到集群中,而不会导致中断。
-
副本管理:Deployment负责管理Pod的副本,可以指定应用程序需要的副本数量,Deployment将根据需求来自动调整。
-
声明性配置:Deployment的配置是声明性的,你只需定义所需的状态,而不是详细指定如何实现它。Kubernetes会根据你的声明来管理应用程序的状态。
4.1 部署deployment
下面使用 deployment.yaml 作为示例进行演示:
$ kk apply -f deployment.yaml deployment.apps/hellok8s-go-http created # 查看启动的pod $ kk get deployments NAME READY UP-TO-DATE AVAILABLE AGE hellok8s-go-http 2/2 2 2 3m
还可以查看pod运行的node:
# 这里的IP是pod ip,属于部署k8s集群时规划的pod网段 # NODE就是集群中的node名称 $ kk get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES hellok8s-go-http-55cfd74847-5jw7f 1/1 Running 0 68s 20.2.36.75 k8s-node1 <none> <none> hellok8s-go-http-55cfd74847-zlf49 1/1 Running 0 68s 20.2.36.74 k8s-node1 <none> <none>
删除pod会自动重启一个新的Pod,确保可用的pod数量与deployment.yaml中的replicas字段保持一致,不再演示。
4.2 修改deployment
修改方式仍然支持修改模板文件和使用patch命令两种。
现在以修改模板中的replicas=3为例进行演示。为了能够观察pod数量变化过程,提前打开一个终端执行kk get pods --watch命令。
下面是演示情况:
# --watch可简写为-w
$ kk get pods --watch
NAME READY STATUS RESTARTS AGE
hellok8s-go-http-58cb496c84-cft9j 1/1 Running 0 4m7s
# 在另一个终端执行patch命令
# kk patch deployment hellok8s-go-http -p '{"spec":{"replicas": 3}}'
hellok8s-go-http-58cb496c84-sdrt2 0/1 Pending 0 0s
hellok8s-go-http-58cb496c84-sdrt2 0/1 Pending 0 0s
hellok8s-go-http-58cb496c84-pjkp9 0/1 Pending 0 0s
hellok8s-go-http-58cb496c84-pjkp9 0/1 Pending 0 0s
hellok8s-go-http-58cb496c84-sdrt2 0/1 ContainerCreating 0 0s
hellok8s-go-http-58cb496c84-pjkp9 0/1 ContainerCreating 0 0s
hellok8s-go-http-58cb496c84-pjkp9 1/1 Running 0 1s
hellok8s-go-http-58cb496c84-sdrt2 1/1 Running 0 1s
最后,你可以通过kk get pods命令观察到Deployment管理下的pod副本数量为3。
我们可以在Deployment创建后修改它的部分字段,比如标签、副本数以及容器模板。其中修改容器模板会触发Deployment管理的所有Pod更新。
4.3 更新deployment
这一步通过修改main.go来模拟实际项目中的服务更新,修改后的文件是 main2.go。
重新构建&推送镜像:
docker build . -t leigg/hellok8s:v2 docker push leigg/hellok8s:v2
然后更新deployment:
# set image是一种命令式的更新操作,是一种临时性的操作方式,会导致当前状态与YAML清单定义不一致,生产环境中不推荐; # 生产环境推荐通过修改YAML清单再apply的方式进行更新 $ kk set image deployment/hellok8s-go-http hellok8s=leigg/hellok8s:v2 $ # 查看更新过程(如果镜像已经拉取,此过程会很快,你可能只会看到最后一条输出) $ kk rollout status deployment/hellok8s-go-http Waiting for deployment "hellok8s-go-http" rollout to finish: 2 out of 3 new replicas have been updated... Waiting for deployment "hellok8s-go-http" rollout to finish: 2 out of 3 new replicas have been updated... Waiting for deployment "hellok8s-go-http" rollout to finish: 2 out of 3 new replicas have been updated... Waiting for deployment "hellok8s-go-http" rollout to finish: 1 old replicas are pending termination... Waiting for deployment "hellok8s-go-http" rollout to finish: 1 old replicas are pending termination... deployment "hellok8s-go-http" successfully rolled out # 也可以直接查看pod信息,会观察到pod正在更新(这是一个启动新pod,删除旧pod的过程,最终会维持到所配置的replicas数量) $ kk get po -w NAMESPACE NAME READY STATUS RESTARTS AGE default go-http 1/1 Running 0 14m default hellok8s-go-http-55cfd74847-5jw7f 1/1 Terminating 0 3m default hellok8s-go-http-55cfd74847-z29dl 1/1 Running 0 3m default hellok8s-go-http-55cfd74847-zlf49 1/1 Running 0 3m default hellok8s-go-http-668c7f75bd-m56pm 0/1 ContainerCreating 0 0s default hellok8s-go-http-668c7f75bd-qlrk5 1/1 Running 0 14s # 绑定其中一个pod来测试(这是一个阻塞终端的操作) $ kk port-forward hellok8s-go-http-668c7f75bd-m56pm 3000:3000 Forwarding from 127.0.0.1:3000 -> 3000 Forwarding from [::1]:3000 -> 3000
在另一个会话窗口执行
$ curl http://localhost:3000 [v2] Hello, Kubernetes!
这里演示的更新是容器更新,修改其他属性也属于更新。
通过
kk get deploy -o wide或kk describe deploy ...命令可以查看Pod内每个容器使用的镜像名称(含版本)。
Deployment的镜像更新或回滚都是通过 创建新的ReplicaSet和终止旧的ReplicaSet 来完成的,你可以通过kk get rs -w来观察这一过程。
在更新完成后,应当看到新旧ReplicaSet是同时存在的:
$ kk get rs -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR hellok8s-go-http-55cfd74847 0 0 0 7m50s hellok8s leigg/hellok8s:v1 app=hellok8s,pod-template-hash=55cfd74847 hellok8s-go-http-668c7f75bd 3 3 3 6m23s hellok8s leigg/hellok8s:v2 app=hellok8s,pod-template-hash=668c7f75bd
注意
:k8s使用旧的ReplicaSet作为Deployment的更新历史,回滚时会用到,所以请不要手动删除旧的ReplicaSet。通过kubectl rollout history deployment/hellok8s-go-http
可以查看上线历史:
$ kk rollout history deployment/hellok8s-go-http deployment.apps/hellok8s-go-http REVISION CHANGE-CAUSE 1 <none> 2 <none>
其中CHANGE-CAUSE列是更新原因,可以通过以下命令设置当前运行版本(REVISION)的备注:
$ kubectl annotate deployment/hellok8s-go-http kubernetes.io/change-cause="image updated to v2"
deployment.apps/hellok8s-go-http annotated
$ kk rollout history deployment/hellok8s-go-http
deployment.apps/hellok8s-go-http
REVISION CHANGE-CAUSE
1 <none>
2 image updated to v2
只有当Deployment的.spec.template部分发生变更时才会创建新的REVISION,如果只是Pod数量变化或Deployment标签修改,则不会创建新的REVISION。
4.4 回滚部署
如果新的镜像无法正常启动,则旧的pod不会被删除,但需要回滚,使deployment回到正常状态。
按照下面的步骤进行:
- 修改main.go为 main_panic.go ;
- 构建镜像:
docker build . -t leigg/hellok8s:v2_problem - push镜像:
docker push leigg/hellok8s:v2_problem - 更新deployment使用的镜像:
kk set image deployment/hellok8s-go-http hellok8s=leigg/hellok8s:v2_problem - 观察:
kk rollout status deployment/hellok8s-go-http(会停滞,按 Ctrl-C 停止观察) - 观察pod:
kk get pods
$ kk get pods NAME READY STATUS RESTARTS AGE go-http 1/1 Running 0 36m hellok8s-go-http-55cfd74847-fv2kp 1/1 Running 0 17m hellok8s-go-http-55cfd74847-l78pb 1/1 Running 0 17m hellok8s-go-http-55cfd74847-qtb59 1/1 Running 0 17m hellok8s-go-http-7c9d684dd-msj2c 0/1 CrashLoopBackOff 1 (4s ago) 6s # CrashLoopBackOff状态表示重启次数过多,过一会儿再试,这表示pod内的容器无法正常启动,或者启动就立即退出了 # 查看每个副本集每次更新的pod情况(包含副本数量、上线时间、使用的镜像tag) # DESIRED-预期数量,CURRENT-当前数量,READY-可用数量 # -l 进行标签筛选 $ kk get rs -l app=hellok8s -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR hellok8s-go-http-55cfd74847 0 0 0 76s hellok8s leigg/hellok8s:v1 app=hellok8s,pod-template-hash=55cfd74847 hellok8s-go-http-668c7f75bd 3 3 3 55s hellok8s leigg/hellok8s:v2 app=hellok8s,pod-template-hash=668c7f75bd hellok8s-go-http-7c9d684dd 1 1 0 11s hellok8s leigg/hellok8s:v2_problem app=hellok8s,pod-template-hash=7c9d684dd
现在进行回滚:
# 先查看deployment更新记录
$ kk rollout history deployment/hellok8s-go-http
deployment.apps/hellok8s-go-http
REVISION CHANGE-CAUSE
1 <none>
2 image updated to v2
3 <none>
# 现在回到revision 2,可以先查看它具体信息(主要确认用的哪个镜像tag)
$ kk rollout history deployment/hellok8s-go-http --revision=2
deployment.apps/hellok8s-go-http with revision #2
Pod Template:
Labels: app=hellok8s
pod-template-hash=668c7f75bd
Containers:
hellok8s:
Image: leigg/hellok8s:v2
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
# 确认后再回滚(若不指定--to-revision=N,则是回到上个版本)
$ kk rollout undo deployment/hellok8s-go-http
deployment.apps/hellok8s-go-http rolled back
# 检查副本集状态(所处的版本)
$ kk get rs -l app=hellok8s -o wide
hellok8s-go-http-55cfd74847 0 0 0 9m31s hellok8s leigg/hellok8s:v1 app=hellok8s,pod-template-hash=55cfd74847
hellok8s-go-http-668c7f75bd 3 3 3 9m10s hellok8s leigg/hellok8s:v2 app=hellok8s,pod-template-hash=668c7f75bd
hellok8s-go-http-7c9d684dd 0 0 0 8m26s hellok8s leigg/hellok8s:v2_problem app=hellok8s,pod-template-hash=7c9d684dd
# 恢复正常
$ kk get deployments hellok8s-go-http
NAME READY UP-TO-DATE AVAILABLE AGE
hellok8s-go-http 3/3 3 3 7m42s
4.5 滚动更新(Rolling Update)
k8s 1.15版本起支持滚动更新,即先创建新的pod,创建成功后再删除旧的pod,确保更新过程无感知,大大降低对业务影响。
在 deployment 的资源定义中, spec.strategy.type 有两种选择:
- RollingUpdate: 逐渐增加新版本的 pod,逐渐减少旧版本的 pod。(常用)
- Recreate: 在新版本的 pod 增加前,先将所有旧版本 pod 删除(针对那些不能多进程部署的服务)
另外,还可以通过以下字段来控制升级 pod 的速率:
- maxSurge: 最大峰值,用来指定可以创建的超出期望 Pod 个数的 Pod 数量。
- maxUnavailable: 最大不可用,用来指定更新过程中不可用的 Pod 的个数上限。
如果不设置,deployment会有默认的配置:
$ kk describe -f deployment.yaml Name: hellok8s-go-http Namespace: default CreationTimestamp: Sun, 13 Aug 2023 21:09:33 +0800 Labels: <none> Annotations: deployment.kubernetes.io/revision: 1 Selector: app=aaa,app1=hellok8s Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge # <------ 看这 省略。。。
为了明确地指定deployment的更新方式,我们需要在yaml中配置:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-go-http
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
replicas: 3
省略其他熟悉的配置项。。。
这样,我们通过kk apply命令时会以滚动更新方式进行。
从
maxSurge: 1可以看出更新时最多会出现4个pod,从maxUnavailable: 1可以看出最少会有2个pod正常运行。
注意:无论是通过kk set image ...还是kk rollout restart deployment xxx方式更新deployment都会遵循配置进行滚动更新。
4.6 控制Pod水平伸缩
# 指定副本数量 $ kk scale deployment/hellok8s-go-http --replicas=10 deployment.apps/hellok8s-go-http scaled # 观察到副本集版本并没有变化,而是数量发生变化 $ kk get rs -l app=hellok8s -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR hellok8s-go-http-55cfd74847 0 0 0 33m hellok8s leigg/hellok8s:v1 app=hellok8s,pod-template-hash=55cfd74847 hellok8s-go-http-668c7f75bd 10 10 10 33m hellok8s leigg/hellok8s:v2 app=hellok8s,pod-template-hash=668c7f75bd hellok8s-go-http-7c9d684dd 0 0 0 32m hellok8s leigg/hellok8s:v2_problem app=hellok8s,pod-template-hash=7c9d684dd
4.7 存活探针 (livenessProb)
存活探测器来确定什么时候要重启容器。 例如,存活探测器可以探测到应用死锁(应用程序在运行,但是无法继续执行后面的步骤)情况。
重启这种状态下的容器有助于提高应用的可用性,即使其中存在缺陷。
下面更新app代码为main_liveness.go,并且构建新的镜像以及推送到远程仓库:
docker build . -t leigg/hellok8s:liveness docker push leigg/hellok8s:liveness
然后在deployment.yaml内添加存活探针配置:
apiVersion: apps/v1
kind: Deployment
metadata:
# deployment唯一名称
name: hellok8s-go-http
spec:
replicas: 2 # 副本数量
selector:
matchLabels:
app: hellok8s # 管理template下所有 app=hellok8s的pod,(要求和template.metadata.labels完全一致!!!否则无法部署deployment)
template: # template 定义一组pod
metadata:
labels:
app: hellok8s
spec:
containers:
- image: leigg/hellok8s:v1
name: hellok8s
# 存活探针
livenessProbe:
# http get 探测指定pod提供HTTP服务的路径和端口
httpGet:
path: /healthz
port: 3000
# 3s后开始探测
initialDelaySeconds: 3
# 每3s探测一次
periodSeconds: 3
更新deployment:
kk apply -f deployment.yaml kk set image deployment/hellok8s-go-http hellok8s=leigg/hellok8s:liveness
现在pod将在15s后一直重启:
$ kk get pods NAME READY STATUS RESTARTS AGE hellok8s-go-http-7d948dfc79-jwjrm 1/1 Running 2 (10s ago) 58s hellok8s-go-http-7d948dfc79-wpk2d 1/1 Running 2 (11s ago) 59s #可以看到探针失败原因 $ kk describe pod hellok8s-go-http-7d948dfc79-wpk2d ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 113s default-scheduler Successfully assigned default/hellok8s-go-http-7d948dfc79-wpk2d to k8s-node1 Normal Pulled 41s (x4 over 113s) kubelet Container image "leigg/hellok8s:liveness" already present on machine Normal Created 41s (x4 over 113s) kubelet Created container hellok8s Normal Started 41s (x4 over 113s) kubelet Started container hellok8s Normal Killing 41s (x3 over 89s) kubelet Container hellok8s failed liveness probe, will be restarted Warning Unhealthy 23s (x10 over 95s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
还有其他探测方式,比如TCP、gRPC、Shell命令。
4.8 就绪探针 (readiness)
就绪探测器可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。
这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。若 Pod 尚未就绪,会被从 Service 的负载均衡器中剔除。
如果一个Pod升级后不能就绪,就不应该允许流量进入该Pod,否则升级完成后导致所有服务不可用。
下面更新app代码为main_readiness.go,并且构建新的镜像以及推送到远程仓库:
docker build . -t leigg/hellok8s:readiness docker push leigg/hellok8s:readiness
然后修改配置文件为 deployment_readiness.yaml
更新deployment:
kk apply -f deployment.yaml kk set image deployment/hellok8s-go-http hellok8s=leigg/hellok8s:readiness
现在可以发现两个 pod 一直处于没有 Ready 的状态当中,通过 describe
命令可以看到是因为 Readiness probe failed: HTTP probe failed with statuscode: 500的原因。
又因为设置了最大不可用的服务数量为maxUnavailable=1,这样能保证剩下两个 v2 版本的 hellok8s 能继续提供服务。
$ kk get pods NAME READY STATUS RESTARTS AGE hellok8s-go-http-764849969-9rtdw 1/1 Running 0 10m hellok8s-go-http-764849969-qfqds 1/1 Running 0 10m hellok8s-go-http-7b778ccdcd-c9kv4 0/1 Running 0 5s hellok8s-go-http-7b778ccdcd-fn7p6 0/1 Running 0 5s $ kk describe pod hellok8s-go-http-7b778ccdcd-c9kv4 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 112s default-scheduler Successfully assigned default/hellok8s-go-http-7b778ccdcd-c9kv4 to k8s-node1 Normal Pulled 111s kubelet Container image "leigg/hellok8s:readiness" already present on machine Normal Created 111s kubelet Created container hellok8s Normal Started 111s kubelet Started container hellok8s Warning Unhealthy 21s (x22 over 110s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 500
4.9 更新的暂停与恢复
在更新时,有时候我们希望先更新1个Pod,通过监控各项指标日志来验证没问题后,再继续更新其他Pod。这个需求可以通过暂停和恢复Deployment来解决。
这也叫做金丝雀发布。
这里会用到的暂停和恢复命令如下:
kk rollout pause deploy {deploy-name}
kk rollout resume deploy {deploy-name}
操作步骤如下:
# 一次性执行两条命令 kk set image deploy hellok8s-go-http=leigg/hellok8s:v2 kk rollout pause deploy hellok8s-go-http # 现在观察更新情况,会发现只有一个pod被更新 kk get pods # 如果此刻想要回滚 kk rollout undo deployment hellok8s-go-http --to-revision=N # 若要继续更新 kk rollout resume deploy hellok8s-go-http
另一种稍微麻烦但更稳妥的方式是部署一个使用新镜像的Deployment,
它与旧Deployment有着相同标签组但不同名(比如deployment-xxx-v2),
相同标签可以让新Deployment与旧Deployment同时接收外部流量,若新Deployment稳定运行一段时间后没有问题则停止旧Deployment。
4.10 底层控制器ReplicaSet
实际上,Pod的副本集功能并不是由Deployment直接提供的,而是由Deployment管理的 ReplicaSet 控制器来提供的。
ReplicaSet 是一个相比Deployment更低级的控制器,它负责维护一组在任何时候都处于运行状态且符合预期数量的 Pod 副本的稳定集合。
然而由于 ReplicaSet 不具备滚动更新和回滚等一些业务常用的流水线功能,所以通常情况下,我们更推荐使用
Deployment或DaemonSet等其他控制器 而不是直接使用
ReplicaSet。你可以通过 官方文档
了解更多ReplicaSet细节。
replicaset.yaml 是一个可参考的示例。
5. 使用DaemonSet
DaemonSet是一种特殊的控制器,它确保会在集群的每个节点(或大部分)上都运行 一个
Pod副本。在节点加入或退出集群时,DaemonSet也会在相应节点增加或删除Pod。
因此常用来部署那些为节点本身提供服务或维护的Pod(如日志收集和转发、监控等)。
因为这一特性,DaemonSet应用通常会在模板中直接指定映射容器端口到节点端口,不用担心同一个节点会运行多个Pod副本而导致端口冲突。
DaemonSet通常会运行在每个节点上,但不包括master节点。因为master节点默认存在不允许调度Pod的 污点
,所以一般会在模板中为Pod配置污点容忍度来实现在master节点上运行DaemonSet Pod(如果不需要在master节点运行则无需配置)。
关于污点,会在 Kubernetes 进阶教程—污点和容忍度 一节中讲到,此处可以先不用深究。
daemonset.yaml 是一个DaemonSet的模板示例。它的管理命令与Deployment没有较大差别,只是DaemonSet不基于ReplicaSet。
具体演示如下:
$ kk apply -f daemonset.yaml daemonset.apps/daemonset-hellok8s-go-http created $ kk get daemonset NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset-hellok8s-go-http 2 2 2 2 2 <none> 8s $ kk get po -o wide|grep daemonset daemonset-hellok8s-go-http-gwbsh 1/1 Running 0 51s 20.2.36.75 k8s-node1 <none> <none> daemonset-hellok8s-go-http-v44jm 1/1 Running 0 51s 20.2.36.74 k8s-master <none> <none> $ kk set image daemonset/daemonset-hellok8s-go-http hellok8s=leigg/hellok8s:v2 daemonset.apps/daemonset-hellok8s-go-http image updated $ kk rollout status daemonset/daemonset-hellok8s-go-http daemon set "daemonset-hellok8s-go-http" successfully rolled out $ kk rollout history daemonset/daemonset-hellok8s-go-http daemonset.apps/daemonset-hellok8s-go-http REVISION CHANGE-CAUSE 1 <none> 2 <none> $ kk get daemonset -o wide NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR daemonset-hellok8s-go-http 2 2 2 2 2 <none> 15m hellok8s leigg/hellok8s:v2 app=hellok8s
6. 使用Job和CronJob
Job和CronJob控制器与Deployment、Daemonset都是同级的控制器。它俩都是用来执行一次性任务的,区别在于Job是一次性的,而CronJob是周期性的。
本节笔者使用k8s官方提供的 playground平台 来进行测试,简单几步就可以搭建起一个临时的多节点k8s集群,
这里也推荐使用,练习/演示必备。(当然读者也可以使用已经搭建好的集群进行测试)
6.1 使用Job
具体来说,Job控制器可以执行3种类型的任务。
- 一次性任务:启动一个Pod(除非启动失败)。一旦Pod成功终止,Job就算完成了。
- 串行式任务:连续、多次地执行某个任务,上一个任务完成后,立即执行下个任务,直到全部执行完。
- 并行式任务:可以通过spec.completions属性指定执行次数。
使用 job.yaml 测试一次性任务:
[node1 ~]$ kk apply -f job.yaml job.batch/pods-job created [node1 ~]$ kk get job NAME COMPLETIONS DURATION AGE pods-job 0/1 19s 19s # DURATION 表示job启动到结束耗时 [node1 ~]$ kk get job NAME COMPLETIONS DURATION AGE pods-job 1/1 36s 60s # Completed 表示pod正常终止 [node1 ~]$ kk get pods NAME READY STATUS RESTARTS AGE pods-simple-pod-kdjr6 0/1 Completed 0 4m41s # 查看pod日志(标准输出和错误) [node1 ~]$ kk logs pods-simple-pod-kdjr6 Start Job! Job Done! # 执行结束后,手动删除job,也可在yaml中配置自动删除 [node1 ~]$ kk delete job pods-job job.batch "pods-job" deleted
配置文件中启动completions字段来设置任务需要执行的总次数(串行式任务),启动parallelism字段来设置任务并发数量(并行式任务)。
处理异常情况
任务执行失败,可以通过backoffLimit字段设置失败重试次数,默认是6次。并且推荐设置restartPolicy为Never(而不是OnFailure),
这样可以保留启动失败的Pod,以便排查日志。
6.2 使用CronJob
它是基于Job的更高级的控制器,添加了时间管理功能。可以实现:
- 在未来某个指定时间运行一次Job
- 周期性运行Job
使用 job.yaml 测试:
[node1 ~]$ kk apply -f cronjob.yaml job.batch/pods-cronjob created [node1 ~]$ kk get cronjob NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE pods-cronjob */1 * * * * False 1 28s 10s # cronjob内部还是调用的job [node1 ~]$ kk get job NAME COMPLETIONS DURATION AGE pods-cronjob-28305226 1/1 34s 2m54s pods-cronjob-28305227 1/1 34s 114s pods-cronjob-28305228 1/1 34s 54s # 删除cronjob,会自动删除关联的job, pod [node1 ~]$ kk delete cronjob pods-cronjob cronjob.batch "pods-cronjob" deleted [node1 ~]$ kk get job No resources found in default namespace.
6.3 其他控制器
除了前面介绍的Deployment、DaemonSet、Job和CronJob控制器,其他还有:
- ReplicationController和ReplicaSetController
- StatefulController
关于ReplicationController和ReplicaSetController
在早期的k8s版本中,ReplicationController是最早提供的控制器,后来ReplicaSetController出现并替代了前者,二者没有本质上的区别,
后者支持复合式的selector。在Deployment出现后,由于它们缺少其他后来新增控制器的更细粒度的生命周期管理功能,
导致ReplicationController和ReplicaSetController已经很少使用,但仍然保留下来。
在后来的版本中,一般都是创建Deployment控制器,由它自动托管ReplicaSetController,用户无需操心后者(但可以命令查看)。
ReplicaSetController也可通过模板创建,可自行查询。需要注意的是,手动创建的ReplicaSetController不能由Deployment控制器托管,
所以ReplicaSetController也不具有滚动更新、版本查看和回滚功能。
StatefulController
这是一种提供排序和唯一性保证的特殊Pod控制器,将在后面的章节中进行介绍。
下一节,将介绍前面这些 Controller 控制的Pod集合如何有效且稳定的对外暴露服务。
7. 使用Service
先提出几个问题:
- 在前面的内容中,我们通过
port-forward的临时方式来访问pod,需要指定某个pod名称,而如果pod发生扩容或重启,pod名称就会变化,
那如何获取稳定的pod访问地址呢? - deployment通常会包含多个pod,如何进行负载均衡?
Service 就是用来解决上述问题的。
Kubernetes 提供了一种名叫 Service 的资源帮助解决这些问题,它为Pod提供一个可稳定访问的端点(以ServiceName作为虚拟域名的形式)。Service
位于Pod的前面,负责接收请求并将它们传递给它后面的所有Pod。 在Service内部动态维护了一组Pod资源的访问端点(Endpoints),一旦服务中的
Pod集合发生更改,Endpoints 就会被更新,请求的重定向自然也会导向最新的Pod。
Service为Pod提供了网络访问、负载均衡以及服务发现等功能。从网络分层上看,Service是作为一个四层网络代理。
7.1 不同类型的Service
Kubernetes提供了多种类型的Service,包括ClusterIP、NodePort、LoadBalancer、Headless和ExternalName,每种类型服务不同的需求和用例。
Service类型的选择取决于你的应用程序的具体要求以及你希望如何将其暴露到网络中。
- ClusterIP:
- 原理:使用这种方式发布时,会为Service提供一个固定的集群内部虚拟IP,供集群内(包含节点)访问。
- 场景:内部数据库服务、内部API服务等。
- NodePort:
- 原理:通过每个节点上的 IP 和静态端口发布服务。 这是一种基于ClusterIP的发布方式,因为它应用后首先会生成一个集群内部IP,
然后再将其绑定到节点的IP和端口,这样就可以在集群外通过nodeIp:port的方式访问服务。 - 场景:Web应用程序、REST API等。
- 原理:通过每个节点上的 IP 和静态端口发布服务。 这是一种基于ClusterIP的发布方式,因为它应用后首先会生成一个集群内部IP,
- LoadBalancer:
- 原理:这种方式又基于 NodePort,另外还会使用到外部由云厂商提供的负载均衡器。由后者向外发布 Service。
一般在使用云平台提供的Kubernetes集群时,会用到这种方式。 - 场景:Web应用程序、公开的API服务等。
- 原理:这种方式又基于 NodePort,另外还会使用到外部由云厂商提供的负载均衡器。由后者向外发布 Service。
- Headless:
- 原理:这种方式不会分配任何集群IP,也不会通过Kube-proxy进行反向代理和负载均衡,而是通过DNS提供稳定的网络ID来访问,
并且DNS会将无头Service的后端解析为Pod的后端IP列表,以供集群内访问(不含节点),属于向内发布。 - 场景:一般提供给StatefulSet使用。
- 原理:这种方式不会分配任何集群IP,也不会通过Kube-proxy进行反向代理和负载均衡,而是通过DNS提供稳定的网络ID来访问,
- ExternalName:
- 原理:与上面提到的发布方式不太相同,这种方式是通过CNAME机制将外部服务引入集群内部,为集群内提供服务,属于向内发布。
- 场景:连接到外部数据库服务、外部认证服务等。
7.2 Service类型之ClusterIP
ClusterIP通过分配集群内部IP来在集群内(包含节点)暴露服务,这样就可以在集群内通过 clusterIP:port 访问到pod服务,集群外则无法访问。
ClusterIP又可以叫做Service VIP(虚拟IP)。
这种方式适用于那些不需要对外暴露的集群内基础设施服务,如节点守护agent/数据库等。
准备工作:
- 修改main.go为 main_hostname.go
- 重新构建和推送镜像
docker build . -t leigg/hellok8s:v3_hostname docker push leigg/hellok8s:v3_hostname
- 更新deployment使用的image
kk set image deployment/hellok8s-go-http hellok8s=leigg/hellok8s:v3_hostname # 等待pod更新 kk get pods --watch
- deployment更新成功后,编写 Service 配置文件 service-clusterip.yaml
- 应用Service配置文件,并观察Endpoint资源
kk apply -f service-clusterip.yaml $ kk get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 20.1.0.1 <none> 443/TCP 11h service-hellok8s-clusterip ClusterIP 20.1.120.16 <none> 3000/TCP 20s $ kk get endpoints NAME ENDPOINTS AGE kubernetes 10.0.2.2:6443 6h54m service-hellok8s-clusterip 20.2.36.72:3000,20.2.36.73:3000 6m38s
这里通过kk get svc获取到的就是集群内default空间下的service列表,我们发布的自然是第二个,它的ClusterIP是20.1.120.16,
这个IP是可以在节点直接访问的:
$ curl 20.1.120.16:3000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-dstff # 多次访问,会观察到hostname变化,说明service进行了负载均衡 $ curl 20.1.120.16:3000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-wtdht
然后我们通过kk get endpoints获取到的是Service后端的逻辑Pod组的信息,ENDPOINTS
列中包含的两个地址则是两个就绪的pod的访问地址(这个IP是Pod专属网段,节点无法直接访问),
这些端点是和就绪的pod保持一致的(Service会实时跟踪),下面通过控制Pod数量增减来观察。
在 Kubernetes 中,Endpoints 是一种资源对象,用于指定与一个 Service 关联的后端 Pod 的 IP 地址和端口信息。
Endpoints 对象充当服务发现机制的一部分,它告诉 Kubernetes 如何将流量路由到 Service 的后端 Pod。Endpoints一般都是通过Service自动生成的,Service会自动跟踪关联的Pod,当Pod状态发生变化时会自动更新Endpoints。
$ kk scale deployment/hellok8s-go-http --replicas=3 deployment.apps/hellok8s-go-http scaled $ kk get endpoints NAME ENDPOINTS AGE kubernetes 10.0.2.2:6443 7h3m service-hellok8s-clusterip 20.2.36.72:3000,20.2.36.73:3000,20.2.36.74:3000 15m $ kk scale deployment/hellok8s-go-http --replicas=2 deployment.apps/hellok8s-go-http scaled # 注意pod ip可能发生变化 $ kk get endpoints NAME ENDPOINTS AGE kubernetes 10.0.2.2:6443 7h5m service-hellok8s-clusterip 20.2.36.72:3000,20.2.36.75:3000 17m
ClusterIP除了在节点上可直接访问,在集群内也是可以访问的。下面启动一个Nginx Pod来访问这个虚拟的ClusterIP (20.1.120.16)。
- 定义 pod_nginx.yaml,并应用它,不再演示。(
可提前在node上拉取镜像:ctr -n k8s.io images pull docker.io/library/nginx:latest) - 进入nginx pod shell,尝试访问
service-hellok8s-clusterip提供的endpoint
$ kk get pods --watch NAME READY STATUS RESTARTS AGE hellok8s-go-http-6bb87f8cb5-dstff 1/1 Running 0 27m hellok8s-go-http-6bb87f8cb5-wtdht 1/1 Running 0 11m nginx 1/1 Running 0 11s # 进入 nginx pod $ kk exec -it nginx -- bash kk exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kk exec [POD] -- [COMMAND] instead. # 访问 hellok8s 的 cluster ip root@nginx:/# curl 20.1.120.16:3000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-dstff root@nginx:/# curl 20.1.120.16:3000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-wtdht
Service访问及负载均衡原理
如果还记得文章开头的架构图,就会发现每个节点都运行着一个kube-proxy组件,这个组件会跟踪Service和Pod的动态变化,并且最新
的Service和Pod的映射关系会被记录到每个节点的iptables中,这样每个节点上的iptables规则都会随着Service和Pod资源自动更新。
iptables使用NAT技术将虚拟IP(也叫做VIP)的流量转发到Endpoint。
通过在master节点(其他节点也可)iptables -L -v -n -t nat可以查看其配置,这个结果会很长。这里贴出关键的两条链:
$ iptables -L -v -n -t nat
...
Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-SVC-JD5MR3NA4I4DYORP tcp -- * * 0.0.0.0/0 20.1.0.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
6 360 KUBE-SVC-BRULDGNIV2IQDBPU tcp -- * * 0.0.0.0/0 20.1.120.16 /* default/service-hellok8s-clusterip cluster IP */ tcp dpt:3000
0 0 KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- * * 0.0.0.0/0 20.1.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:443
0 0 KUBE-SVC-TCOU7JCQXEZGVUNU udp -- * * 0.0.0.0/0 20.1.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:53
0 0 KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- * * 0.0.0.0/0 20.1.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:53
1079 64740 KUBE-NODEPORTS all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
Chain KUBE-SVC-BRULDGNIV2IQDBPU (1 references)
pkts bytes target prot opt in out source destination
6 360 KUBE-MARK-MASQ tcp -- * * !20.2.0.0/16 20.1.120.16 /* default/service-hellok8s-clusterip cluster IP */ tcp dpt:3000
2 120 KUBE-SEP-JCBKJJ6OJ3DPB6OD all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/service-hellok8s-clusterip -> 20.2.36.77:3000 */ statistic mode random probability 0.50000000000
4 240 KUBE-SEP-YHSEP23J6IVZKCOG all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/service-hellok8s-clusterip -> 20.2.36.78:3000 */
...
这里有 KUBE-SERVICES和 KUBE-SVC-BRULDGNIV2IQDBPU两条链,前者引用了后者。第一条链中,可以看到目标为20.1.120.16
的流量将被转发至KUBE-SVC-BRULDGNIV2IQDBPU链,即第二条链。在第二条链中又定义了3条转发规则:
- 第一条规则会对源不是
20.2.0.0/16地址范围内且目标端口是3000的所有tcp数据包执行MASQ动作,即NAT操作(转发时执行源IP替换) - 第二条规则将任意链内流量转发到目标
KUBE-SEP-JCBKJJ6OJ3DPB6OD,尾部probability说明应用此规则的概率是0.5 - 第三条规则将任意链内流量转发到目标
KUBE-SEP-YHSEP23J6IVZKCOG,概率也是0.5(1-0.5)
而这2和3两条规则中的目标其实就是指向两个后端Pod IP,可通过iptables-save | grep KUBE-SEP-YHSEP23J6IVZKCOG查看其中一个目标明细:
$ iptables-save | grep KUBE-SEP-YHSEP23J6IVZKCOG :KUBE-SEP-YHSEP23J6IVZKCOG - [0:0] -A KUBE-SEP-YHSEP23J6IVZKCOG -s 20.2.36.78/32 -m comment --comment "default/service-hellok8s-clusterip" -j KUBE-MARK-MASQ -A KUBE-SEP-YHSEP23J6IVZKCOG -p tcp -m comment --comment "default/service-hellok8s-clusterip" -m tcp -j DNAT --to-destination 20.2.36.78:3000 -A KUBE-SVC-BRULDGNIV2IQDBPU -m comment --comment "default/service-hellok8s-clusterip -> 20.2.36.78:3000" -j KUBE-SEP-YHSEP23J6IVZKCOG $ kk get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES hellok8s-go-http-6bb87f8cb5-dstff 1/1 Running 0 53m 20.2.36.77 k8s-node1 <none> <none> hellok8s-go-http-6bb87f8cb5-wtdht 1/1 Running 0 52m 20.2.36.78 k8s-node1 <none> <none>
可以看到链KUBE-SEP-YHSEP23J6IVZKCOG的规则之一就是将转入的流量全部转发到目标20.2.36.78:3000
,这个IP也是名字为hellok8s-go-http-6bb87f8cb5-wtdht的Pod的内部IP。
7.3 Service类型之NodePort
ClusterIP 只能在集群内访问Pod服务,而 NodePort 则进一步将服务暴露到集群节点的静态端口上,可以认为NodePort是ClusterIP的增强模式。
比如k8s集群有2个节点:node1和node2,暴露后就可以通过 node1-ip:port 或 node2-ip:port 的方式来稳定访问Pod服务。
操作步骤:
- 定义 service-nodeport.yaml,并应用;
- 通过访问k8s集群中的任一节点ip+端口进行验证
具体指令如下:
# 同样会分配一个 cluster-ip $ kk get svc service-hellok8s-nodeport NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service-hellok8s-nodeport NodePort 20.1.252.217 <none> 3000:30000/TCP 79s # 在节点10.0.2.2 上访问 本机端口 以及 节点 10.0.2.3:30000 # - 同样每个ip访问2次验证负载均衡功能 $ curl 10.0.2.2:30000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-hx7pv $ curl 10.0.2.2:30000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-4bddw $ curl 10.0.2.3:30000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-hx7pv $ curl 10.0.2.3:30000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-4bddw
7.4 Service类型之LoadBalancer
上一节的NodePort是通过节点端口的方式向外暴露服务,这其实已经距离集群外访问服务只有一步之遥了。此时我们有两种方式在集群外访问服务:
- 第一种是比较简单的方式:使用节点的公网IP进行访问(将节点IP配置到域名A记录同理)
- 第二种是比较稳妥的方式:单独部署一套负载均衡服务(它会再提供一个VIP供外部访问),负责将集群外部的流量转发到集群内部。
- 负载均衡服务一般是做四层转发(大部分也支持七层转发),主要作用是防DDos攻击以及提高应用并发的能力。
- 现代云厂商一般都有提供软件负载均衡服务产品,并且支持按需的防DDos攻击能力、跨地区容灾等Nginx具备或不具备的能力。
LoadBalancer 正是通过使用云厂商提供的负载均衡器(Service LoadBalancer,一般叫做SLB)的高可用方式向外暴露服务。
负载均衡器将集群外的流量转发到集群内的Node,后者再基于ClusterIP的方式转发到Pod。可以说 LoadBalancer 是 NodePort 的进一步增强。
假如你在 AWS 的 EKS 集群上创建一个 Type 为 LoadBalancer 的 Service。它会自动创建一个 ELB (Elastic Load Balancer)
,并可以根据配置的 IP 池中自动分配一个独立的 IP 地址,可以供外部访问。
这一步由于没有条件,不再演示。LoadBalancer 架构图如下:
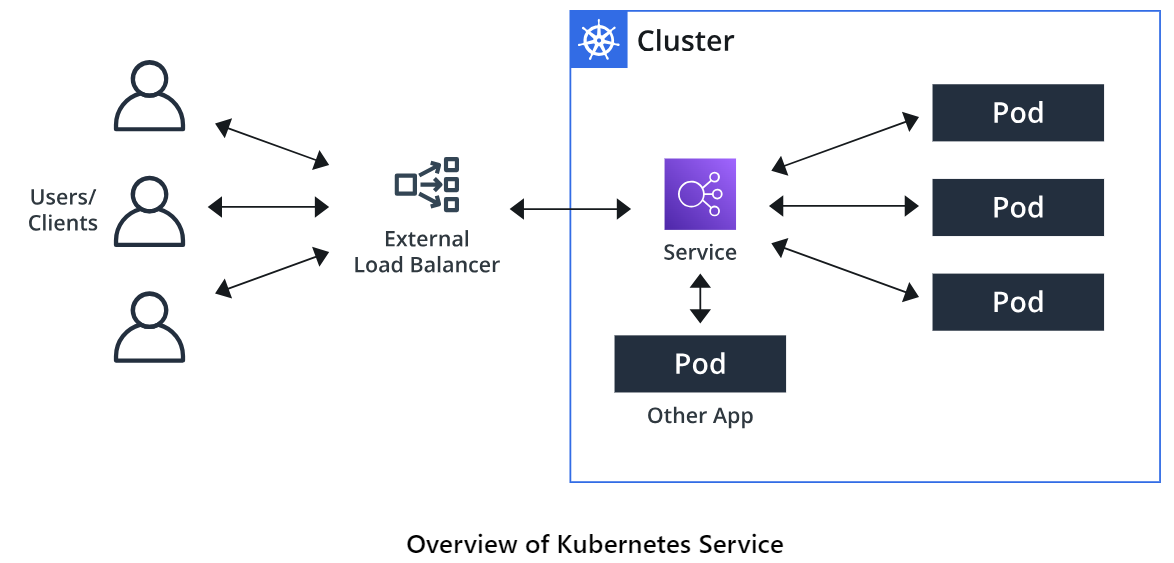
从架构图可看出,LoadBalancer是基于 NodePort
的一种Service,这里提供模板供参考:service-loadbalancer.yaml
所以如果是使用公有云托管的k8s集群,那么通常也会使用它们提供的SLB服务。若是自己搭建的集群,
那么一般也不会使用LoadBalancer(私有集群一般也不支持LoadBalancer)。
7.5 Service类型之Headless
这是一种特殊的Service类型,它不为整个服务分配任何集群IP,而是通过分配的DNS域名来访问Pod服务。由于没有Cluster
IP,所以节点和集群外都无法直接访问Service(但可以在节点直接访问Pod IP)。无头Service主要提供给StatefulSet(如数据库集群)使用。
操作步骤:
- 定义 service-clusterip-headless.yaml,并应用;
- 定义 pod_curl.yaml 并应用(具有curl和nslookup命令),用来作为client访问定义好的service;
- 进入curl容器,使用curl和nslookup命令进行访问测试;
具体指令如下:
kk apply -f service-clusterip-headless.yaml kk apply -f pod_curl.yaml # 进入curl容器 kk exec -it curl -- /bin/sh # 访问测试 / # curl service-hellok8s-clusterip-headless.default.svc.cluster.local:3000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-57r86 / # curl service-hellok8s-clusterip-headless.default.svc.cluster.local:3000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-lgtgf # CNAME记录查询 / # nslookup service-hellok8s-clusterip-headless.default.svc.cluster.local nslookup: can't resolve '(null)': Name does not resolve Name: service-hellok8s-clusterip-headless.default.svc.cluster.local Address 1: 20.2.36.77 20-2-36-77.service-hellok8s-clusterip-headless.default.svc.cluster.local Address 2: 20.2.36.78 20-2-36-78.service-hellok8s-clusterip-headless.default.svc.cluster.local
这里的service-hellok8s-clusterip-headless.default.svc.cluster.local就是Service提供给集群内部访问Pod组的域名,
组成方式为{ServiceName}.{Namespace}.svc.{ClusterDomain},其中ClusterDomain表示集群域,默认为cluster.local,Namespace在Service的yaml文件中未指定那就是default。
在上述操作中,我们通过curl进行了访问测试,可以看到没问题,但是并不提供负载均衡功能,读者可多访问几次进行观察。
然后我们通过nslookup查看域名的DNS信息,可以看到Service域名指向两个Pod IP,并且它们还有对应的专有域名,但因为Pod IP非固定,
所以这个专有域名也没任何作用。
除了直接调用域名访问服务之外,还可解析域名来根据需求决定访问哪个Pod。这种方式更适合StatefulSet产生的有状态Pod。
7.6 Service类型之ExternalName
ExternalName 也是k8s中一个特殊的Service类型,它不需要设置selector去选择为哪些pods实例提供服务,而是使用DNS
CNAME机制把svc指向另外一个域名,这个域名可以是任何能够访问的虚拟地址(不可以是IP),
比如mysql.db.svc这样的建立在db命名空间内的mysql服务,也可以指定www.baidu.com这样的外部真实域名。
比如可以定义一个service指向 www.baidu.com,然后可以在集群内的任何一个pod上访问这个service的域名,
请求service域名将自动重定向到www.baidu.com。
注意: ExternalName 这个类型也仅在集群内(不含节点)可访问。
操作步骤:
- 定义 service-externalname.yaml,并应用
- 进入上一节中准备好的curl容器,使用curl和nslookup命令进行访问测试;
具体指令如下:
$ kk apply -f service-externalname.yaml # 进入curl容器 $ kk exec -it curl -- /bin/sh / # ping service-hellok8s-externalname.default.svc.cluster.local PING service-hellok8s-externalname.default.svc.cluster.local (14.119.104.254): 56 data bytes 64 bytes from 14.119.104.254: seq=0 ttl=54 time=9.353 ms 64 bytes from 14.119.104.254: seq=1 ttl=54 time=9.278 ms ^C --- service-hellok8s-externalname.default.svc.cluster.local ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 9.278/9.315/9.353 ms / # nslookup service-hellok8s-externalname.default.svc.cluster.local nslookup: can't resolve '(null)': Name does not resolve Name: service-hellok8s-externalname.default.svc.cluster.local Address 1: 14.119.104.189 Address 2: 14.119.104.254 Address 3: 240e:ff:e020:37::ff:b08c:124f Address 4: 240e:ff:e020:38::ff:b06d:569b
注意:这里无法通过curl测试达到访问百度的效果,笔者推断是因为curl在使用service域名访问时只能拿到www.baidu.com
,拿不到百度服务器IP,即curl不具备DNS解析功能,所以无法正常访问百度获取到HTML。而ping工具可以执行DNS解析,所以能够拿到IP。
用途说明:ExternalName 类Service一般用在集群内部需要调用外部服务的时候,比如云服务商部署的DB等服务。
无头Service + Endpoints
另外,很多时候,比如是自己部署的DB服务,只有IP而没有域名,ExternalName
是无法实现这个需求的,需要使用 无头Service+Endpoints来实现,
这里提供一个测试通过的模板 service-headless-endpoints.yaml 供读者自行练习。
Endpoints对象一般不需要手动创建,Service controller会在service创建时自动创建,只有在需要关联集群外的服务时可能用到。
这个时候就可定义Endpoints模板,其中填入外部服务的IP和端口,然后应用即可。如果集群外的服务提供的地址是域名而不是IP,则使用
ExternalName。
7.7 搭配ExternalIP
前面小节介绍的 ClusterIP(含Headless)/NodePort/LoadBalancer/ExternalName 五种Service都可以搭配 ExternalIP 使用,
ExternalIP是Service模板中的一个配置字段,位置是spec.externalIP。配置此字段后,在原模板提供的功能基础上,
还可以将Service注册到指定的ExternalIP(通常是节点网段内的空闲IP)上,从而增加Service的一种暴露方式。
这里提供一个测试通过的模板 service-clusterip-externalip.yaml 给读者自行练习。
spec.externalIP可以配置为任意局域网IP,而不必是节点网段内的ip,Service Controller会自动为每个节点添加路由。
注意:设置
spec.externalIP时要选择一个当前网络中没有使用以及以后大概率也不会使用的IP(例如192.168.255.100),
避免在访问Service时出现乌龙。
7.8 服务发现
k8s支持下面两种服务发现方式:
- kube-dns(推荐)
- 环境变量
7.8.1 kube-dns
如果你足够细心,你可能已经发现了kube-system空间下有个名为kube-dns的service,这个service就是k8s内置的DNS组件,
它用来为集群中所有Pod提供服务发现功能。这个service通过selectork8s-app=kube-dns关联了名为coredns的Pod组。
$ kk get pod,deployment,svc -nkube-system |grep dns pod/coredns-c676cc86f-4vzdl 1/1 Running 1 (2d14h ago) 2d17h pod/coredns-c676cc86f-v8s8k 1/1 Running 1 (2d14h ago) 2d17h deployment.apps/coredns 2/2 2 2 2d18h service/kube-dns ClusterIP 20.1.0.10 <none> 53/UDP,53/TCP,9153/TCP 2d18h
k8s通过每个节点部署的kubelet组件向每个新启动的Pod注入DNS配置(通过/etc/resolv.conf),从而实现服务发现。这里随意选择一个Pod,
查看DNS配置。
$ kk exec -it hellok8s-go-http-6bb87f8cb5-c6bvs -- cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 20.1.0.10 options ndots:5
详细解释这个配置:
search default.svc.cluster.local svc.cluster.local cluster.local
这一行定义了DNS搜索域。它告诉DNS解析器,如果在域名中没有明确指定的主机名,那么应该依次尝试附加这些搜索域来查找主机名。
在这种情况下,如果你尝试解析一个名为example的主机名,DNS解析器会首先尝试example.default.svc.cluster.local,
然后是example.svc.cluster.local,最后是example.cluster.local。这对于Kubernetes集群中的服务发现非常有用,
因为它允许你使用短名称来引用服务,而不必指定完整的域名。nameserver 20.1.0.10
这一行指定了要使用的DNS服务器的IP地址(对应kube-dns的ClusterIP)。在这种情况下,DNS解析器将查询由IP地址20.1.0.10
指定的DNS服务器(即pod/coredns)来解析域名。options ndots:5
这一行定义了DNS解析选项。ndots是一个数字,表示DNS解析器应该在域名中查找多少次点(.)以确定绝对域名。在这种情况下,
ndots:5表示如果一个域名中包含至少5个点,则DNS解析器会将它视为绝对域名,否则会依次附加搜索域来查找主机名。
比如现在有如下部署:
$ kk get pod,svc NAME READY STATUS RESTARTS AGE pod/hellok8s-go-http-6bb87f8cb5-c6bvs 1/1 Running 0 3h7m pod/hellok8s-go-http-6bb87f8cb5-g8fmd 1/1 Running 0 3h7m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 20.1.0.1 <none> 443/TCP 3h36m service/service-hellok8s-clusterip ClusterIP 20.1.151.162 <none> 3000/TCP 3h33m
那么service-hellok8s-clusterip就是一个集群内有效的虚拟主机名(指向两个hellok8s-go-httpPod),我们可以启动一个curl
容器来测试:
$ kk apply -f pod_curl.yaml pod/curl created $ kk exec -it curl -- curl service-hellok8s-clusterip:3000 [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-g8fmd
有了内置的服务发现功能,我们在部署微服务项目时就无需再单独部署如consul这样的服务发现组件了,节省了不少的开发及维护工作。
7.8.2 环境变量
在每个新启动的Pod中,kubelet也会向其以环境变量形式注入当前Namespace中已存在的Service连接信息,Pod可以通过这些环境变量来发现其他Service的IP地址。
这里假设已经启动了service/service-hellok8s-clusterip,然后重新启动pod/curl
,然后在后者shell中查看service/service-hellok8s-clusterip的环境变量:
$ kk exec -it curl -- printenv |grep HELLOK8S SERVICE_HELLOK8S_CLUSTERIP_PORT_3000_TCP_PORT=3000 SERVICE_HELLOK8S_CLUSTERIP_PORT_3000_TCP=tcp://20.1.151.162:3000 SERVICE_HELLOK8S_CLUSTERIP_PORT_3000_TCP_ADDR=20.1.151.162 SERVICE_HELLOK8S_CLUSTERIP_SERVICE_HOST=20.1.151.162 SERVICE_HELLOK8S_CLUSTERIP_PORT=tcp://20.1.151.162:3000 SERVICE_HELLOK8S_CLUSTERIP_SERVICE_PORT=3000 SERVICE_HELLOK8S_CLUSTERIP_PORT_3000_TCP_PROTO=tcp
所以此时我们也可以通过env的方式访问service/service-hellok8s-clusterip:
$ kk exec -it curl -- sh / # curl $SERVICE_HELLOK8S_CLUSTERIP_SERVICE_HOST:$SERVICE_HELLOK8S_CLUSTERIP_SERVICE_PORT [v3] Hello, Kubernetes!, From host: hellok8s-go-http-6bb87f8cb5-g8fmd
但是,环境变量方式对资源的创建顺序有要求。比如pod/curl先启动,某个service后创建,那么启动后的pod/curl
中就不会有这个Service相关的环境变量。
所以这里不推荐使用环境变量的方式访问Service,而是推荐使用内置DNS的方式。
关闭Service Env注入
通过上面内容我们可以估算到,在一个Namespace中若存在1000个Service,就会给新创建的Pod注入7000个Env变量。
巨多的Env变量会导致某些编程语言开发的应用所运行的容器崩溃(也可能表现为容器的CPU/内存占用高),比如Java,Nodejs等。
所以我们可以在创建Pod时,通过设置spec.enableServiceLinks: false参数来关闭Service Env注入。
关闭Service Env注入不会影响模板中的其他Env变量注入。
参考:
8. 使用Ingress
上一章节中,我们知道有以下几种方式可以实现对外暴露服务:
- NodePort(Pod设置HostNetWork同理)
- LoadBalancer
- ExternalIP
但在实际环境中,我们很少直接使用这些方式来对外暴露服务,因为它们都有一个比较严重的问题,那就是需要占用节点端口。也就是说,占用节点端口的数量会随着服务数量的增加而增加,这就产生了很大的端口管理成本。
除此之外,这些方式也不支持域名以及SSL配置(除了LoadBalancer),还需要额外配置其他具有丰富功能的反向代理组件,如Nginx、Kong等。
Ingress就是为了解决这些问题而设计的,它允许你将 Service
映射到集群对外提供的某个端点上(由域名和端口组成的地址),这样我们就可以在Ingress中将多个Service配置到同一个域名的不同路径下对外提供服务,避免了对节点端口的过多占用。
Ingress还支持路由规则和域名配置等高级功能,就像Nginx那样能够承担业务最外层的反向代理+网关的角色。。
举个栗子:集群对外的统一端点是api.example.com:80,可以这样为集群内的两个Service(backend:8080、frontend:8082)配置对外端点映射:
- api.example.com/backend 指向 backend:8080
- api.example.com/frontend 指向 frontend:8082
除此之外,Ingress还可以为多个域名配置不同的路由规则,在仅占用单个节点端口的同时实现灵活的路由配置功能。
总的来说,Ingress提供以下功能:
- 路由规则:Ingress 允许你定义路由规则,使请求根据主机名和路径匹配路由到不同的后端服务。这使得可以在同一 IP
地址和端口上公开多个服务。 - Rewrite 规则:Ingress 支持 URL 重写,允许你在路由过程中修改请求的 URL 路径;
- TLS/SSL 支持:你可以为 Ingress 配置 TLS 证书,以加密传输到后端服务的流量;
- 负载均衡:Ingress 可以与云提供商的负载均衡器集成,以提供外部负载均衡和高可用性;
- 虚拟主机:你可以配置多个主机名(虚拟主机)来公开不同的服务。这意味着你可以在同一 IP 地址上托管多个域名;
- 自定义错误页面:你可以定义自定义错误页面,以提供用户友好的错误信息;
- 插件和控制器:社区提供了多个 Ingress 控制器,如 Nginx Ingress Controller 和 Traefik,它们为 Ingress 提供了更多功能和灵活性。
Ingress 可以简单理解为集群服务的网关(Gateway),它是所有流量的入口,经过配置的路由规则,将流量重定向到后端的服务。从网络分层上看,Ingress是作为一个七层网络代理。
但是在使用 LoadBalancer 的方式时,Ingress就不是最外层的流量入口了,而是接收来自 LoadBalancer 传入的流量再进行二次路由转发。
8.1 Ingress控制器
使用Ingress时一般涉及2个组件:
- Ingress:是 Kubernetes 中的一种 API 资源类型,它定义了从集群外部访问集群内服务的规则。通常,这些规则涉及到 HTTP 和
HTTPS 流量的路由和负载均衡。
Ingress 对象本身只是一种规则定义,它需要一个 Ingress 控制器来实际执行这些规则。 - Ingress 控制器:是 Kubernetes 集群中的一个独立组件或服务,以Pod形式存在。它实际处理 Ingress 规则,根据这些规则配置集群中的代理服务器(如
Nginx、Traefik 等)来处理流量路由和负载均衡。- Ingress 控制器负责监视 Ingress 对象的变化,然后动态更新代理服务器的配置以反映这些变化。Kubernetes社区提供了一些不同的
Ingress 控制器,您可以根据需求选择合适的控制器。 - Ingress 控制器是实际承载流量转发的组件。每次更新Ingress规则后,都会动态加载到控制器中。
- Ingress 控制器负责监视 Ingress 对象的变化,然后动态更新代理服务器的配置以反映这些变化。Kubernetes社区提供了一些不同的
使用Ingress访问服务的流量链路如下:
- 用户流量通过公网DNS流入Ingress Controller Pod
- Ingress Controller Pod根据配置的规则找到并转发流量给对应后端服务所在的Node
- (下面描述的是在集群内通过ServiceName访问服务的流量转发流程)
- 首先会通过集群内的CoreDNS服务查询ServiceName对应的ClusterIP
- 然后通过节点所在的kube-proxy所配置好的iptables规则将流量转发给Pod所在的Node
- 在iptables规则中可以找到ClusterIP的下一跳,即Pod所在的Node IP
- 若有多个Pod后端,则iptables中也会存在多条能匹配目标ClusterIP的规则,此时会按规则概率进行转发(默认都具有相同概率,也就是均衡)
- Node接收到流量后再根据(kube-proxy所配置好的)本地iptables将流量转发给本地的Pod
如果你使用了LoadBalancer,则用户流量通过公网DNS流入LoadBalancer,后者再通过转发至Ingress Controller Pod,然后继续上述流程。
Ingress控制器不会随集群一起安装,需要单独安装。可以选择的Ingress控制器很多,可查看官方提供的Ingress控制器列表,
再根据情况自行选择,常用的是Nginx、Traefik。
8.2 安装Nginx Ingress控制器
传统架构中常用Nginx作为外部网关,所以这里也使用Nginx作为Ingress控制器来练习。
先通过官方仓库页面的版本支持表确认控制器与k8s匹配的版本信息,笔者使用的k8s版本是1.27.0,准备安装的Nginx
ingress控制器版本是1.8.2。
安装方式有Helm安装和手动安装,Helm是一个很好用的k8s包管理器(在进阶教程中有介绍),但这里先使用手动安装。
# 下载Nginx Ingress控制器安装文件
# 已经 githubusercontent 替换为 gitmirror
wget https://raw.gitmirror.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml -O nginx-ingress.yaml
# 查看需要的镜像
$ cat nginx-ingress.yaml|grep image:
image: registry.k8s.io/ingress-nginx/controller:v1.8.2@sha256:74834d3d25b336b62cabeb8bf7f1d788706e2cf1cfd64022de4137ade8881ff2
image: registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b
image: registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b
$ 在node1上手动拉取镜像(部署的Pod会调度到非Master节点)
$ grep -oP 'image:\s*\K[^[:space:]]+' nginx-ingress.yaml | xargs -n 1 ctr image pull
# 安装
$ kk apply -f nginx-ingress.yaml
# 等待控制器的pod运行正常(这里自动创建了一个新的namespace)
$ kk get pods --namespace=ingress-nginx --watch
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-kt8lm 0/1 Completed 0 2m36s
ingress-nginx-admission-patch-rslxl 0/1 Completed 2 2m36s
ingress-nginx-controller-6f4df7b5d6-lxfsr 1/1 Running 0 2m36s
# 注意前两个 Completed 的pod是一次性的,用于执行初始化工作,现在安装成功。
# 等待各项资源就绪
kk wait --namespace ingress-nginx \
--for=condition=ready pod \
--selector=app.kubernetes.io/component=controller \
--timeout=120s
#查看安装的各种资源
$ kk get all -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-admission-create-smxkz 0/1 Completed 0 16m
pod/ingress-nginx-admission-patch-7c86x 0/1 Completed 1 16m
pod/ingress-nginx-controller-6f4df7b5d6-pz8cp 1/1 Running 0 16m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller LoadBalancer 20.1.115.216 <pending> 80:31888/TCP,443:30158/TCP 16m
service/ingress-nginx-controller-admission ClusterIP 20.1.102.149 <none> 443/TCP 16m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-nginx-controller 1/1 1 1 16m
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-nginx-controller-6f4df7b5d6 1 1 1 16m
NAME COMPLETIONS DURATION AGE
job.batch/ingress-nginx-admission-create 1/1 5s 16m
job.batch/ingress-nginx-admission-patch 1/1 7s 16m
可能会遇到image拉取失败,解决如下:
$ kk get pod -ningress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-csfjc 0/1 ImagePullBackOff 0 5m55s
ingress-nginx-admission-patch-rgdxr 0/1 ImagePullBackOff 0 5m55s
ingress-nginx-controller-6f4df7b5d6-dhfg2 0/1 ContainerCreating 0 5m55s
$ kk describe pod ingress-nginx-admission-create-csfjc -ningress-nginx
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3m6s default-scheduler Successfully assigned ingress-nginx/ingress-nginx-admission-create-csfjc to k8s-node1
Normal BackOff 2m19s kubelet Back-off pulling image "registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b"
Warning Failed 2m19s kubelet Error: ImagePullBackOff
Normal Pulling 2m5s (x2 over 3m20s) kubelet Pulling image "registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b"
Warning Failed 15s (x2 over 2m19s) kubelet Failed to pull image "registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b": rpc error: code = DeadlineExceeded desc = failed to pull and unpack image "registry.k8s.io/ingress-nginx/kube-webhook-certgen@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b": failed to resolve reference "registry.k8s.io/ingress-nginx/kube-webhook-certgen@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b": failed to do request: Head "https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/ingress-nginx/kube-webhook-certgen/manifests/sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b": dial tcp 142.251.8.82:443: i/o timeout
# 发现无法访问 registry.k8s.io,参考 https://github.com/anjia0532/gcr.io_mirror 来解决
# 笔者发起issue来同步nginx用到的几个镜像到作者的docker仓库,大概1min完成同步,然后现在在节点手动拉取这个可访问的docker.io下的镜像进行替代
# 在非master节点执行(ctr是containerd cli):
ctr image pull docker.io/anjia0532/google-containers.ingress-nginx.kube-webhook-certgen:v20230407
ctr image pull docker.io/anjia0532/google-containers.ingress-nginx.controller:v1.8.2
# 替换模板中的镜像(mac环境需要在-i后面加 "",即sed -i "" 's#...')
sed -i 's#registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b#docker.io/anjia0532/google-containers.ingress-nginx.kube-webhook-certgen:v20230407#' nginx-ingress.yaml
sed -i 's#registry.k8s.io/ingress-nginx/controller:v1.8.2@sha256:74834d3d25b336b62cabeb8bf7f1d788706e2cf1cfd64022de4137ade8881ff2#docker.io/anjia0532/google-containers.ingress-nginx.controller:v1.8.2#' nginx-ingress.yaml
# 重新部署
kk delete -f nginx-ingress.yaml --force
kk apply -f nginx-ingress.yaml
这里重点关注service/ingress-nginx-controller这一行,这是Nginx Ingress自动创建的LoadBalancer类型的service,
它会跟踪Ingress配置中的后端Pod组端点变化,并实时更新Pod ingress-nginx-controller中的转发规则,
后者再转发流量到 service-hellok8s-clusterip,然后最终到达业务pod。
所以Nginx Ingress Controller启动后会默认监听节点的两个随机端口(这里是31888/30158),分别对应其Pod内的80/443,
后面讲如何修改为节点固定端口。
8.3 开始测试
准备工作:
- 修改main.go为 main_nginxingress.go
- 重新构建并推送镜像
docker build . -t leigg/hellok8s:v3_nginxingress docker push leigg/hellok8s:v3_nginxingress
- 更新deployment镜像:
kk set image deployment/hellok8s-go-http hellok8s=leigg/hellok8s:v3_nginxingress,并等待更新完成 - 部署 deployment_httpd_svc.yaml 作为 Ingress 后端之一
- 部署 Ingress ingress-hellok8s.yaml,其中定义了路由规则
- 在节点上验证
# 查看部署的资源(省略了不相关的资源) $ kk get pods,svc,ingress NAME READY STATUS RESTARTS AGE pod/hellok8s-go-http-6bb87f8cb5-57r86 1/1 Running 1 (12h ago) 37h pod/hellok8s-go-http-6bb87f8cb5-lgtgf 1/1 Running 1 (12h ago) 37h pod/httpd-69fb5746b6-5v559 1/1 Running 0 97s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/httpd-svc ClusterIP 20.1.140.111 <none> 8080/TCP 97s service/service-hellok8s-clusterip ClusterIP 20.1.112.41 <none> 3000/TCP 28h NAME CLASS HOSTS ADDRESS PORTS AGE ingress.networking.k8s.io/hellok8s-ingress nginx * 80 9m18s # 1-通过clusterIP访问httpd $ curl 20.1.140.111:8080 <html><body><h1>It works!</h1></body></html> # 前一节讲到的nginx 以LoadBalancer类型部署的svc,所以要通过节点访问,需要先获知svc映射到节点的端口号,如下为 80:31504, 443:32548 $ kk get svc -ningress-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress-nginx-controller LoadBalancer 20.1.251.172 <pending> 80:31504/TCP,443:32548/TCP 19h ingress-nginx-controller-admission ClusterIP 20.1.223.76 <none> 443/TCP 19h # 2-通过节点映射端口访问 /httpd $ curl 127.0.0.1:31504/httpd <html><body><h1>It works!</h1></body></html> # 3-通过节点映射端口访问 /hello $ curl 127.0.0.1:31504/hello [v3] Hello, Kubernetes!, this is ingress test, host:hellok8s-go-http-6df8b5c5d7-75qb6
这就是基本的ingress使用步骤,还可以通过kk describe -f ingress-hellok8s.yaml查看具体路由规则。
若要更新路由规则,修改Ingress yaml文件后再次应用即可,通过kk logs -f ingress-nginx-controller-xxx -n ingress-nginx
可以看到请求日志。
这里列出几个常见的配置示例,供读者自行练习:
- 虚拟域名:ingress-hellok8s-host.yaml
- 配置证书:ingress-hellok8s-cert.yaml
- 默认后端:ingress-hellok8s-defaultbackend.yaml
- 正则匹配:ingress-hellok8s-regex.yaml
8.4 Ingress高可靠部署
一般通过多节点部署的方式来实现高可靠,同时Ingress作为业务的流量入口,也建议一个ingress服务独占一个节点的方式进行部署,
避免业务服务与ingress服务发生资源争夺。
也就是说,单独使用一台机器来部署ingress服务,这台机器可以是较低计算性能(如2c4g),但需要较高的上行带宽。
然后再根据业务流量规模(定期观察ingress节点的上行流量走势)进行ingress节点扩缩容。若前期规模不大,也可以ingress节点与业务节点混合部署的方式,
但要注意进行资源限制和隔离。
下面给出常用指令,根据需要使用。
Ingress控制器扩容:
kk -n kube-system scale --replicas=3 deployment/nginx-ingress-controller
指定节点部署ingress(通过打标签):
$ kk label nodes k8s-node1 ingress="true" $ kk get node k8s-node1 --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-node1 Ready <none> 2d22h v1.27.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,ingress=true,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux # 修改ingress部署文件,搜索Deployment,在其spec.template.spec.nodeSelector下面添加 ingress: "true" $ vi deploy.yaml #apiVersion: apps/v1 #kind: Deployment #... # nodeSelector: # kubernetes.io/os: linux # ingress: "true" # <----- 添加这行 #... $ kk apply -f deploy.yaml # 更新部署
注意:默认不能部署到master节点,存在污点问题,需要移除污点才可以,参考 k8s-master增加和删除污点。
8.5 Ingress部署方案推荐
-
Deployment +
LoadBalancer模式的 Service
说明:如果要把Ingress部署到公有云,那用这种方式比较合适。用Deployment部署ingress-controller,创建一个type为LoadBalancer
的 service 关联这组 Pod(这是Nginx Ingress的默认部署方式)。大部分公有云,都会为LoadBalancer的 service
自动创建(并关联)一个负载均衡器,通常还分配了公网IP。
只需要在负载均衡器上配置域名和证书,就实现了集群服务的对外暴露。 -
DaemonSet + HostNetwork + nodeSelector
说明:用DaemonSet结合nodeSelector来部署ingress-controller到特定的node上,然后使用HostNetwork直接把该pod与宿主机node的网络打通,直接使用节点的80/433端口就能访问服务。
这时,ingress-controller所在的node机器就很类似传统架构的边缘节点,比如机房入口的nginx服务器。该方式整个请求链路最简单,性能相对NodePort模式更好。
有一个问题是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller
Pod,但这在生产环境下也不算是问题,只要完成多节点部署实现高可用即可。
然后将Ingress节点公网IP填到域名CNAME记录中即可。
笔者提供测试通过的Ingress-nginx模板供读者练习:ingress-nginx-daemonset-hostnetwork.yaml
,主要修改了3处:Deployment改为DaemonSet- 注释
DaemonSet模块的strategy部分(strategy是Deployment模块下的字段) - 在DaemonSet模块的
spec.template.spec下添加hostNetwork: true
使用这个模板后,可以观察到在k8s-node1上会监听80、443和8443端口(Ingress-nginx需要的端口)。
-
Deployment +
NodePort模式的Service
说明:同样用Deployment模式部署ingress-controller,并创建对应的service,但是type为NodePort。这样,Ingress就会暴露在集群节点ip的特定端口上。
然后可以直接将Ingress节点公网IP填到域名CNAME记录中。
笔者提供测试通过Ingress-nginx模板供读者练习:ingress-nginx-deployment-nodeport.yaml,
主要修改了2处:- Service模块下
spec.ports部分新增nodePort: 30080和nodePort: 30443(注意nodePort对应的端口范围受到限制:30000-32767)
- Service模块下
这种方式可以使用的节点端口受到了固定范围限制,具有一定局限性,应用规划端口时需要考虑到这一点。
练习时,如对Ingress-nginx模板有修改,建议完全删除该模板对应资源(使用kk delete -f deploy.yaml,操作可能会耗时几十秒),否则直接应用可能不会生效。
9. 使用Namespace
Namespace(命名空间)用来隔离集群内不同环境下的资源。仅同一namespace下的资源命名需要唯一,它的作用域仅针对带有名字空间的对象,例如
Deployment、Service 等。
前面的教程中,默认使用的 namespace 是 default。
创建多个namespace:
apiVersion: v1 kind: Namespace metadata: name: dev --- apiVersion: v1 kind: Namespace metadata: name: test
使用:
$ kk apply -f namespaces.yaml # namespace/dev created # namespace/test created $ kk get namespaces # NAME STATUS AGE # default Active 215d # dev Active 2m44s # ingress-nginx Active 110d # kube-node-lease Active 215d # kube-public Active 215d # kube-system Active 215d # test Active 2m44s # 获取指定namespace下的资源 $ kk get pods -n dev
需要注意的是,删除namespace时,会默认删除该空间下的所有资源,需要谨慎操作。
10. 使用ConfigMap和Secret
ConfigMap 和 Secret 都是用来保存配置数据的,在模板定义和使用上没有大太差别。唯一的区别就是Secret是用来保存敏感型的配置数据,比如证书密钥、token之类的。
10.1 ConfigMap
K8s 使用 ConfigMap 来将你的配置数据和应用程序代码分开,将非机密性的数据保存到键值对中。ConfigMap 在设计上不是用来保存大量数据的。
在 ConfigMap 中保存的数据不可超过 1 MiB。如果你需要保存超出此尺寸限制的数据,你需要考虑挂载存储卷。
ConfigMap 可以用四种方式进行使用:
- 在容器命令和参数内
- 容器的环境变量(常见)
- 在只读卷里面添加一个文件,让应用来读取(常见)
- 编写代码在 Pod 中运行,使用 Kubernetes API 来读取 ConfigMap(不常见)
下面使用ConfigMap来保存apphellok8s的配置信息:
# configmap-hellok8s.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: hellok8s-configmap
data: # 用来保存UTF8字符串
DB_URL: "http://mydb.example123.com"
binaryData: # 用来保存二进制数据作为 base64 编码的字串。
app-config.json: eyJkYl91cmwiOiJteXNxbC5leGFtcGxlLmNvbSJ9Cg== # echo '{"db_url":"mysql.example.com"}' |base64
# 对于一个大量使用 configmap 的集群,禁用 configmap 修改会带来以下好处
# 1. 保护应用,使之免受意外(不想要的)更新所带来的负面影响。
# 2. 通过大幅降低对 kube-apiserver 的压力提升集群性能, 这是因为系统会关闭对已标记为不可变更的 configmap 的监视操作。
# 一旦标记为不可更改,这个操作就不可逆,再想要修改就只能删除并重建 configmap
immutable: true
然后修改 deployment 以读取configmap,具体看 deployment-use-configmap.yaml。
然后再修改main.go为 main_read_configmap.go,接着重新构建并推送镜像:
# 先删除所有资源
$ kk delete pod,deployment,service,ingress --all
docker build . -t leigg/hellok8s:v4_configmap
docker push leigg/hellok8s:v4_configmap
kk apply -f deployment-use-configmap.yaml
$ kk get pod
NAME READY STATUS RESTARTS AGE
hellok8s-go-http-684ff55564-qf2x9 1/1 Running 0 3m47s
hellok8s-go-http-684ff55564-s5bfl 1/1 Running 0 3m47s
# pod直接映射到节点端口
$ curl 10.0.2.3:3000/hello
[v4] Hello, Kubernetes! From host: hellok8s-go-http-c548c88b5-25sl9
Get Database Connect URL: http://mydb.example123.com
app-config.json:{"db_url":"mysql.example.com"}
可以看到app已经拿到了configmap中定义的配置信息。若要更新,直接更改configmap的yaml文件然后应用,然后重启业务pod即可(使用kk rollout restart deployment <deployment-name>)。
若configmap配置了immutable: true,则无法再进行修改:
$ kk apply -f configmap-hellok8s.yaml The ConfigMap "hellok8s-configmap" is invalid: data: Forbidden: field is immutable when `immutable` is set
最后需要注意的是,在上面提到的四种使用configmap的方式中,只有挂载volume和调用k8s
API的方式会接收到configmap的更新(具有一定延迟),其余两种则需要重启Pod才能看到更新。
10.2 Secret
Secret用于存储敏感信息,例如密码、Token、(证书)密钥等,在使用上与ConfigMap不会有太大差别,但需要注意下面两点。
data的value部分必须是base64编码后的字符串(创建时会执行base64解码检查),但Pod中获取到的仍然是明文;- 模板语法上稍有不同
- Secret 支持的是
stringData而不是binaryData,它的value可以是任何UTF8字符 - 额外支持
type字段,用来在创建时检查资源合法性
- Secret 支持的是
10.2.1 Secret的类型
创建 Secret 时,还可以使用 Secret 资源的 type 字段(可选),它用来告诉k8s我要创建何种类型的secret,并根据类型对其进行基础的合法性检查。
当前支持的类型如下:
| 类型 | 描述 |
|---|---|
| Opaque | 用户定义的任意数据(默认) |
| kubernetes.io/service-account-token | 服务账号令牌 |
| kubernetes.io/dockercfg | ~/.dockercfg 文件的序列化形式 |
| kubernetes.io/dockerconfigjson | ~/.docker/config.json 文件的序列化形式 |
| kubernetes.io/basic-auth | 用于基本身份认证的凭据 |
| kubernetes.io/ssh-auth | 用于 SSH 身份认证的凭据 |
| kubernetes.io/tls | 用于 TLS 客户端或者服务器端的数据 |
| bootstrap.kubernetes.io/token | 启动引导令牌数据 |
比如type为kubernetes.io/tls时,k8s要求secret中必须包含tls.crt和tls.key两个字段(data或stringData都可),
但这里不会对值进行任何检查,并且这个类型也限制了创建后再修改,只能删除重建。
secret-hellok8s-cert.yaml 是一个合法的kubernetes.io/tls
类型的Secret。其他类型的要求查看官方文档。
10.2.2 引用时设置可选key
正常情况下,如果引用Secret的某个字段不存在,则启动Pod时会报错,比如:
# 在env处引用
...
- name: LOG_LEVEL
valueFrom:
secretKeyRef:
name: hellok8s-secret # name必须是有效且存在的
key: not_found_key
# optional: true
k8s允许在引用Secret时添加optional: true属性,以确保Secret中的字段不存在时不会影响Pod启动(但Secret对象本身必须存在)。
10.2.3 拉取私有镜像使用Secret
如果你尝试从私有仓库拉取容器镜像,你需要一种方式让每个节点上的 kubelet 能够完成与镜像库的身份认证。
你可以配置 imagePullSecrets字段来实现这点。 Secret 是在 Pod 层面来配置的。
有两种方式来配置 imagePullSecrets:
第一种方式需要对使用私有仓库的每个 Pod 执行以上操作,如果App较多,可能比较麻烦。
第二种方式是推荐的方式,因为 ServiceAccount 是一个集群范围内的概念,所以只需要在 ServiceAccount 上添加 Secret,
所有引用该 ServiceAccount 的 Pod 都会自动使用该 Secret。
完整演示这一步需要私有镜像仓库,此节测试略过。
10.2.4 在Pod内测试
笔者提供测试通过的模板和代码供读者自行测试:
测试结果:
$ curl 10.0.2.3:3000/hello [v4] Hello, Kubernetes! From host: hellok8s-go-http-869d4548dc-vtmcr, Get Database Passwd: pass123 some.txt:hello world cert.key:-----BEGIN OPENSSH PRIVATE KEY----- J1a9V50zOAl0k2Fpmy+RDvCy/2LeCZHyWY9MR248Ah2Ko3VywDrevdPIz8bxg9zxqy0+xy jbu09sNix9b0IZuZQbbGkw4C4RcAN5HZ4UnWWRfzv2KgtXSdJCPp38hsWH2j9hmlNXLZz0 EqqtXGJpxjV67NAAAACkxlaWdnQEx1eWk= -----END OPENSSH PRIVATE KEY----- config.yaml:username: hellok8s password: pass123
10.2.5 使用命令创建secret
除了通过模板方式创建Secret,我们还可以通过kubectl命令直接创建Secret:
# generic表示常规类型,通过 kubectl create secret -h 查看参数说明
$ kubectl create secret generic db-user-pass \
--from-literal=username=admin \
--from-literal=password='S!B\*d$zDsb='
secret/db-user-pass created
# 或者通过文件创建
$ kubectl create secret generic db-user-pass \
--from-file=./username.txt \
--from-file=./password.txt
创建后直接查看Secret明文:
$ kk describe secret db-user-pass
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 12 bytes
username: 5 bytes
$ kk get secret db-user-pass -o jsonpath='{.data}'
{"password":"UyFCXCpkJHpEc2I9","username":"YWRtaW4="} # value是base64编码
$ echo UyFCXCpkJHpEc2I9 |base64 --decode
S!B\*d$zDsb=
$ kk get secret db-user-pass -o jsonpath='{.data.password}' | base64 --decode
S!B\*d$zDsb=#
$ kk get secret db-user-pass -o jsonpath='{.data.username}' | base64 --decode
admin
删除Secret:
$ kk delete secret db-user-pass secret "db-user-pass" deleted
10.3 Downward API
有时候,容器需要获得关于自身的信息,但不能与k8s过于耦合,Downward API就是用来解决这个问题的。 Downward API 允许容器在不使用
Kubernetes 客户端或 API 服务器的情况下获得自己或集群的信息,具体通过下面两种方式实现:
- 作为环境变量
- 作为
downwardAPI卷中的文件
这两种暴露 Pod 和容器字段的方式统称为 Downward API。
可用字段
只有部分 Kubernetes API 字段可以通过 Downward API 使用。本节列出了你可以使用的字段。
你可以使用 fieldRef 传递来自可用的 Pod 级字段的信息。
- metadata.name:Pod名称
- metadata.namespace:Pod 的命名空间
- metadata.uid:Pod 的唯一 ID
- metadata.annotations‘
’ :Pod 的注解的值 - metadata.labels‘
’ :Pod 的标签的值
以下信息可以通过环境变量获得,但不能作为 downwardAPI 卷fieldRef 获得:
- spec.serviceAccountName:Pod 的服务账号名称
- spec.nodeName:Pod 运行时所处的节点名称
- status.hostIP:Pod 所在节点的主 IP 地址
- status.hostIPs:这组 IP 地址是 status.hostIP 的双协议栈版本,第一个 IP 始终与 status.hostIP 相同。 该字段在启用了
PodHostIPs 特性门控后可用。 - status.podIP:Pod 的主 IP 地址(通常是其 IPv4 地址)
以下信息可以通过 downwardAPI卷fieldRef 获得,但不能作为环境变量获得:
- metadata.labels:Pod 的所有标签,格式为 标签键名=“转义后的标签值”,每行一个标签
- metadata.annotations:Pod 的全部注解,格式为 注解键名=“转义后的注解值”,每行一个注解
可通过 resourceFieldRef 获得的信息:
- limits.cpu:容器的 CPU 限制值
- requests.cpu:容器的 CPU 请求值
- limits.memory:容器的内存限制值
- requests.memory:容器的内存请求值
- limits.hugepages-*:容器的巨页限制值
- requests.hugepages-*:容器的巨页请求值
- limits.ephemeral-storage:容器的临时存储的限制值
- requests.ephemeral-storage:容器的临时存储的请求值
如果没有为容器指定 CPU 和内存限制时尝试使用 Downward API 暴露该信息,那么 kubelet
默认会根据 节点可分配资源
计算并暴露 CPU 和内存的最大可分配值。
下面使用 pod_use_downwardAPI.yaml 进行测试:
$ kk apply -f pod_use_downwardAPI.yaml pod/busybox-use-downwardapi created $ kk get pod NAME READY STATUS RESTARTS AGE busybox-use-downwardapi 1/1 Running 0 59s $ kk logs busybox-use-downwardapi hellok8s, downwardAPI! PodName=busybox-use-downwardapi LIMITS_CPU=1 POD_IP=20.2.36.86 $ kk exec -it busybox-use-downwardapi -- sh / # ls /config/downward_api_info/ LABELS POD_NAME / # cat /config/downward_api_info/LABELS app="busybox" label_test="some_value" / # cat /config/downward_api_info/POD_NAME busybox-use-downwardapi
结语
恭喜🎉🎉🎉!!!你已经看完了本篇 K8s 基础教程。如果你完成了教程中的大部分练习,相信你已经能够熟练使用 Kubernetes 进行日常开发工作了。
如果你的工作需要深度使用 K8s(比如运维人员)亦或你想要深度掌握K8s的使用,
那请允许我向你推荐Kubernetes 进阶教程。
0 评论