-
由
 虚拟的现实创建于11月 02, 2023
需要 1 分钟阅读时间
虚拟的现实创建于11月 02, 2023
需要 1 分钟阅读时间
Kubernetes CNI
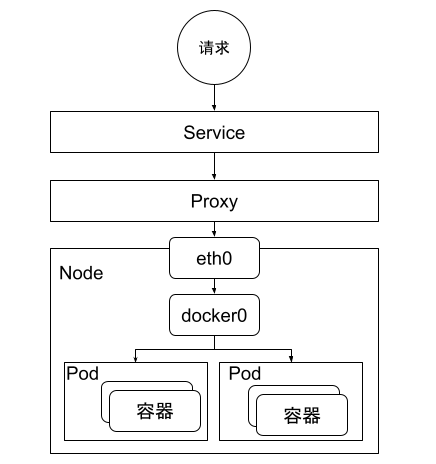
在介绍 CNI 规范之前,我们先了解 Kubernetes 集群内的网络模型定义。
- 每个 Pod 都有一个独立 IP,Pod 内所有的容器共享一个网络命名空间。
- 集群内所有的 Pod 都在一个直连连通的扁平网络中,无需 NAT 就可以互相访问 Node 和容器
- Service Cluster IP 可在集群内部访问。外部请求需要通过 NodePort、LoadBalance 或者 Ingress 访问。
CNI(Container Network Interface) 是 CNCF 项目,定义了一套 Linux 容器网络接口规范,同时也包含了一些插件和实现库。
Kubernetes 本身不实现集群内的网络模型,而是通过将其抽象出来提供了 CNI 接口给第三方实现,这样一来节省了开发资源可以集中精力到 Kubernetes 本身,二来可以利用开源社区的力量打造一整个丰富的生态。
Kubernetes 并不关心各个 CNI 如何具体实现上述基础规则,只要最终的网络模型符合标准即可。因此我们可以确保不论使用什么 CNI,Kubernetes 集群内的 Pod 网络都是一张巨大的平面网络,每个 Pod 在这张网络中地位是平等的,这种设计对于集群内的服务发现、负载均衡、服务迁移、应用配置等诸多场景都带来了极大的便利。
CNI 设计思路
CNI 设计的基本思路是:容器运行时创建网络命令空间 (network namepsace) 后,然后由 CNI 插件负责网络配置,最后启动容器内的应用。CNI 定义了两个插件, CNI plugin 主要用于负责配置网络,以及负责容器地址的 IPAM plugin。我们以容器的启动为例,介绍这两个插件的应用。
- kubelet 在启动容器之前,先启用 Pause 容器。
- Pause 容器启动之前创建网络 namespace。
- 如果 Kubelet 配置了 CNI,会调用对应的 CNI 插件
- CNI 插件执行网络配置操作,如创建虚拟网卡、加入网络空间等。
- CNI 调用 ipam 分配地址。
- 启动 Pod 内其他容器,并共享 Pause 容器内网络空间。
CNI 插件网络方案
当前 CNI 插件主流的方案有以下几种:
-
二层互联,这种方案与传统的 vlan 相结合,弊端是需要再网络硬件上配置 vlan 等信息,不方便管理,并且规模受限,不适用于跨机房互通互联,优点是网络损耗较小,适合小规模集群部署。
-
三层路由,主要是借助 BGP 等三层路由协议完成路由传递。这种方案优势是传输率较高,不需要封包、解包, 但 BGP 等协议在很多数据中心内部支持,设置较为麻烦。
-
Overlay 方案,主要是借助 VXLAN 或者 ipip 等 overlay 协议完成容器互通。 这种方案优点可以完成跨数据中心的网络互联。但弊端是数据封包、解包有一定的计算压力和网络延迟消耗。
-
SDN 方案,主要是借助 SDN 控制器外加 ovs 等虚拟网络交换机完成数据的转发,这种方案的优点是网络可以随意定制,缺点是复杂度较高。
当前主流的网络方案包括 Calico、Weave、Flanne、
添加评论